As an application owner, it is increasingly important to have the ability to analyze large amounts of data. Thankfully, cloud-based Big Data Analytics tools are a widely adopted way to achieve this purpose and AWS offers multiple solutions in this area, particularly the Elastic Map Reduce (EMR) service. EMR delivers a managed solution to deploy tools such as Hadoop, Spark, Hive and Presto, among others, and deploy them in cloud-based compute infrastructure such as EC2 or EKS, or even on-premise servers.
In this article I will focus on Apache Spark, managed by the EMR service, running on EC2 instances.
Infrastructure and Data Setup
Below are the infrastructure and data specifications I used for these tests:
- Test data compliant with the TPC-H benchmark specifications. Tests were executed against 10TB and 30TB datasets in Parquet format. The 10TB TPC-H dataset has close to 87 billion records, while the 30TB dataset has close to 260 billion records (for a total of 347 billion records queried in these tests).
- Data was stored in S3 in the N. Virginia region.
- EMR version 6.11.0 (Spark 3.3.2).
- For EMR Spark to access data, a metadata catalog is required. This was achieved by launching a Hive Metastore, using AWS EMR v.6.11.0 (Hive 3.1.3), with an m5.large EC2 instance and backed by a db.t3.medium AWS RDS MySQL DB instance.
- Tests were executed with clusters consisting of 1 primary node and a different number of executor nodes, depending on the test scenario, all running on r5.8xlarge EC2 instances. Below are the cluster sizes used for these tests:
- 1 Coordinator (r5.8xlarge) + 40 executor nodes (r5.8xlarge)
- 1 Coordinator (r5.8xlarge) + 100 executor nodes (r5.8xlarge)
- For the 10TB tests, the default EBS configuration was applied: 4 128 GB gp2 volumes per node.
- For the 30TB tests, there was 1 EBS volume attached to each node, with the following settings:
VolumeType=gp3, SizeInGB=1000, Iops=3000, Throughput=512 MiB/s - Configured default Spark settings and EMR configuration
maximizeResourceAllocationwas set totrue. EMR delivers an automated way to launch and manage the compute infrastructure of data analytics clusters. It’s important to highlight that cluster launch and management automation can be implemented using the AWS CLI, SDK, or even tools such as CloudFormation.
EMR delivers an automated way to launch and manage the compute infrastructure of data analytics clusters. It’s important to highlight that cluster launch and management automation can be implemented using the AWS CLI, SDK, or even tools such as CloudFormation.
Test Scenarios and Execution
Each test ran the 22 queries defined in the TPC-H benchmark. The whole set of 22 queries was executed 3 times, in a sequential way (queries 1 through 22, executed 3 times). For each query, the average of the 3 executions is the result displayed in the tables and charts in the Test Results section below.
The following test scenarios were executed:
- 10TB - 1 primary node + 40 executor nodes
- 10TB - 1 primary node + 100 executor nodes
- 30TB - 1 primary node + 40 executor nodes
- 30TB - 1 primary node + 100 executor nodes
Test Results
All queries completed successfully for the scenarios in scope. Below are the results for the 10TB scenarios:
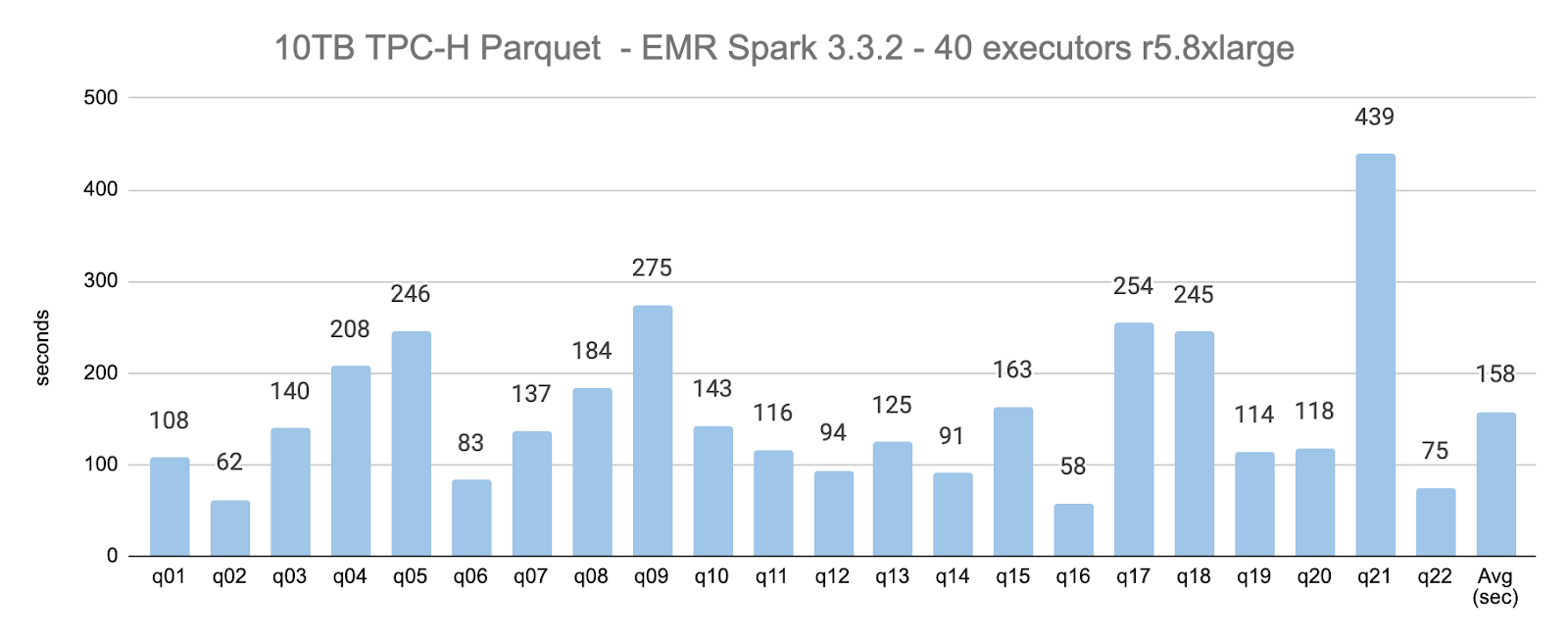
For the 10TB, 40-executors scenario, the average query execution time was 158 seconds.
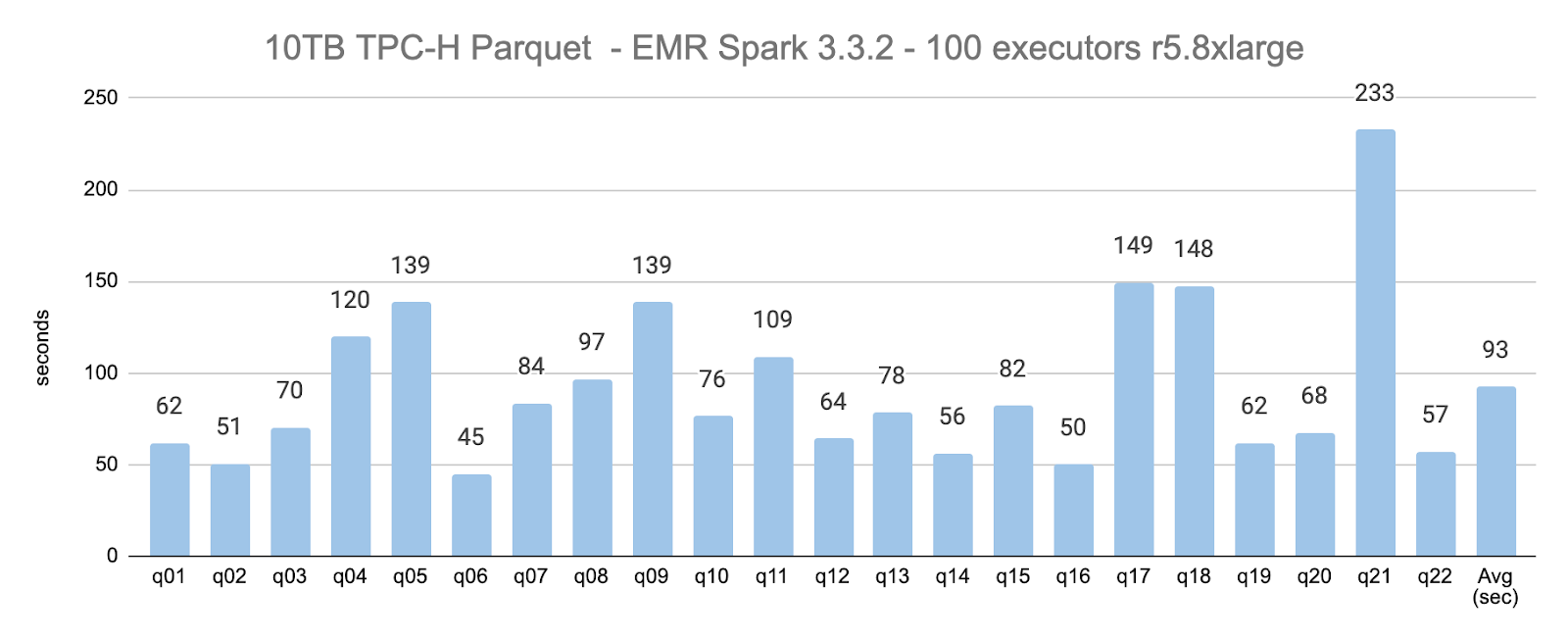
For the 10TB, 100-executors scenario, the average query execution time was 93 seconds (62% the average execution time compared to using 40 executors).
Below are the results for the 30TB scenarios:
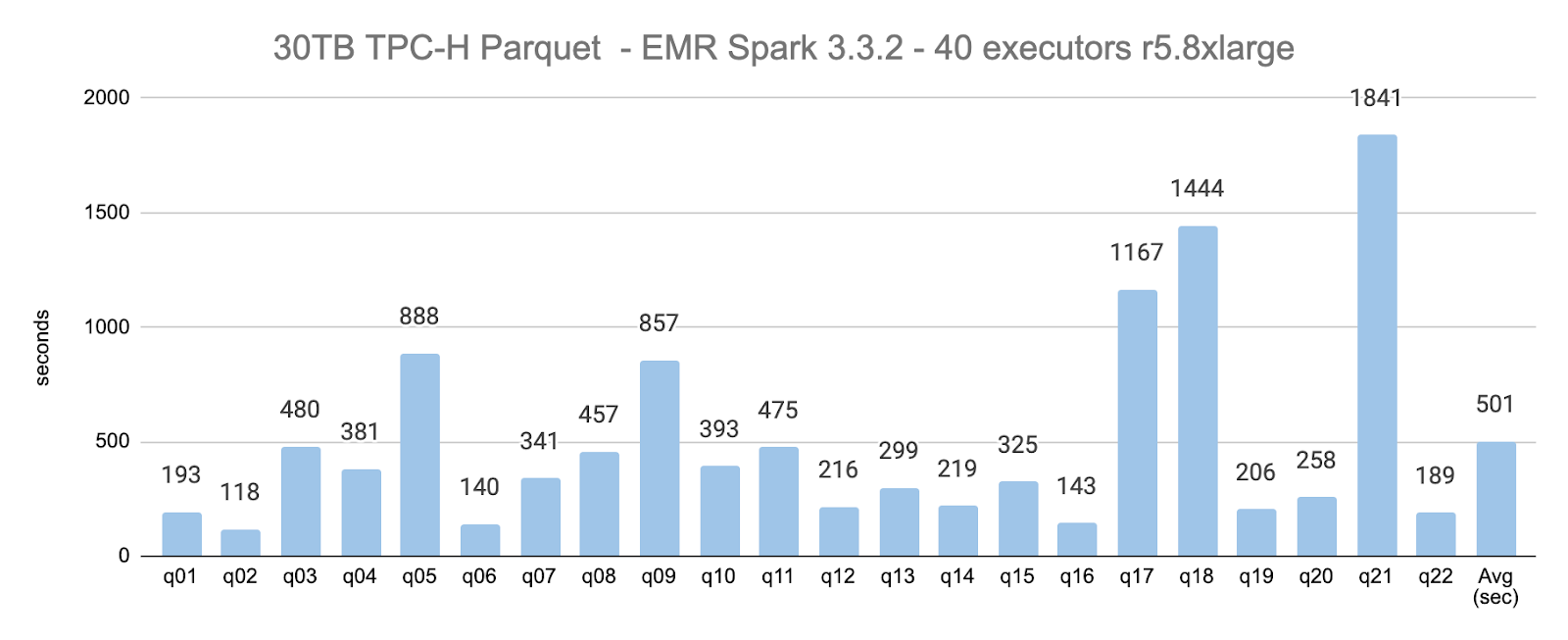
For the 30TB, 40-executors scenario, the average query execution time was 501 seconds (3.17x compared to the 10TB scenario with the same number of nodes).
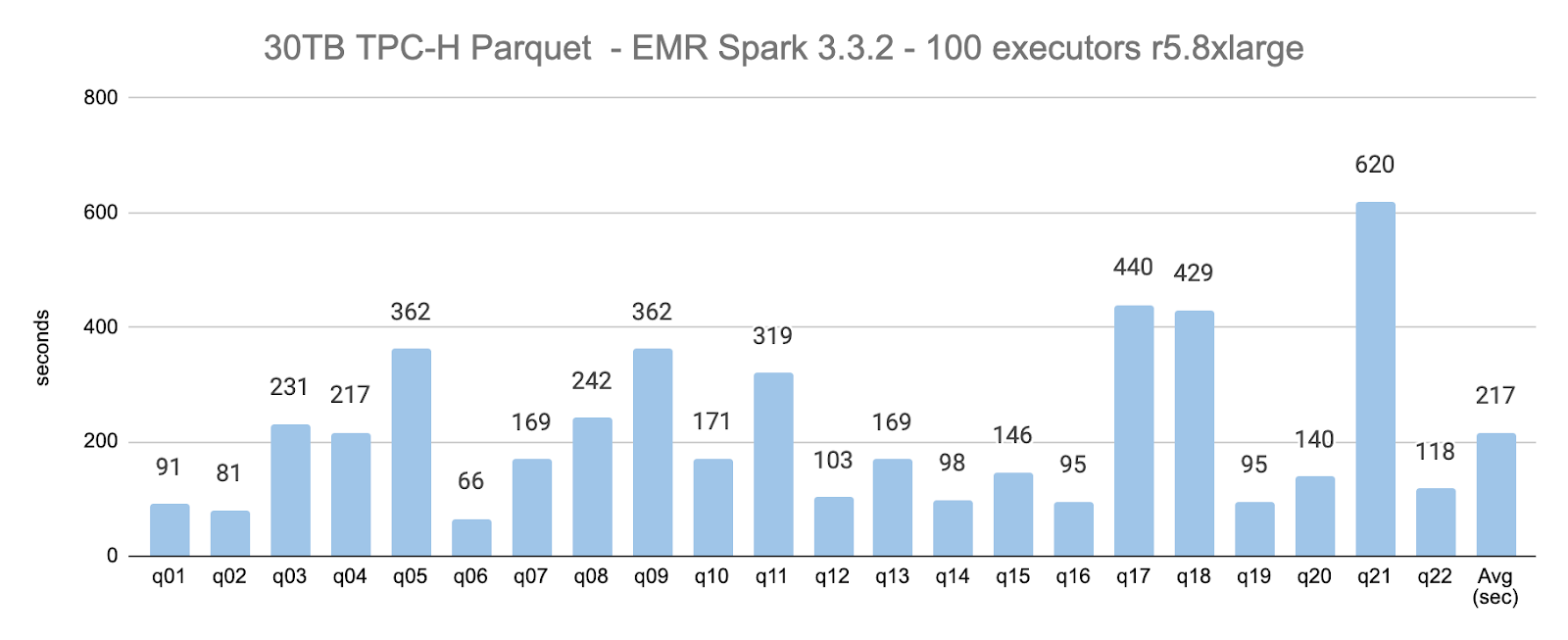
For the 30TB, 100-executors scenario, the average query execution time was 217 seconds (49% the average execution time compared to using 40 executors). 30TB took 2.33x more time to execute compared to 10TB, when using 100 executor nodes.
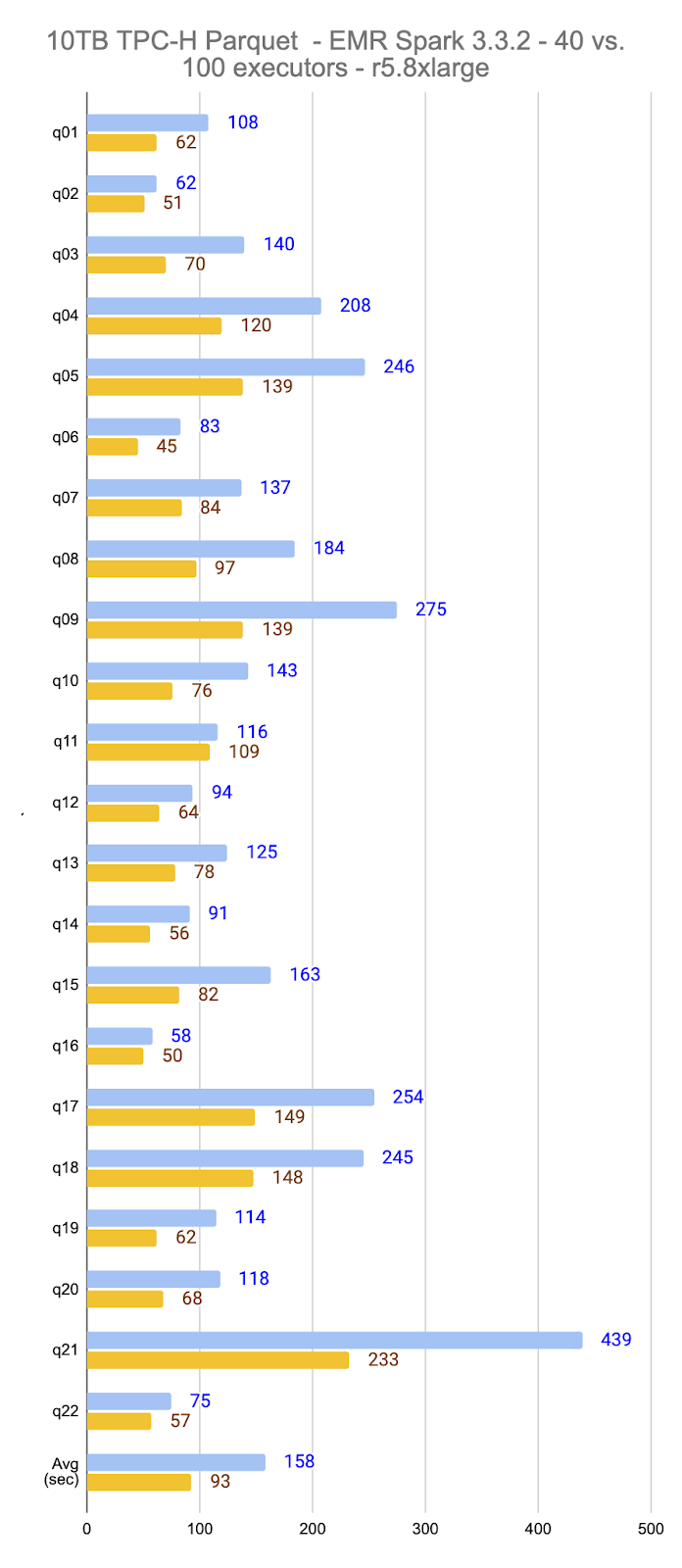
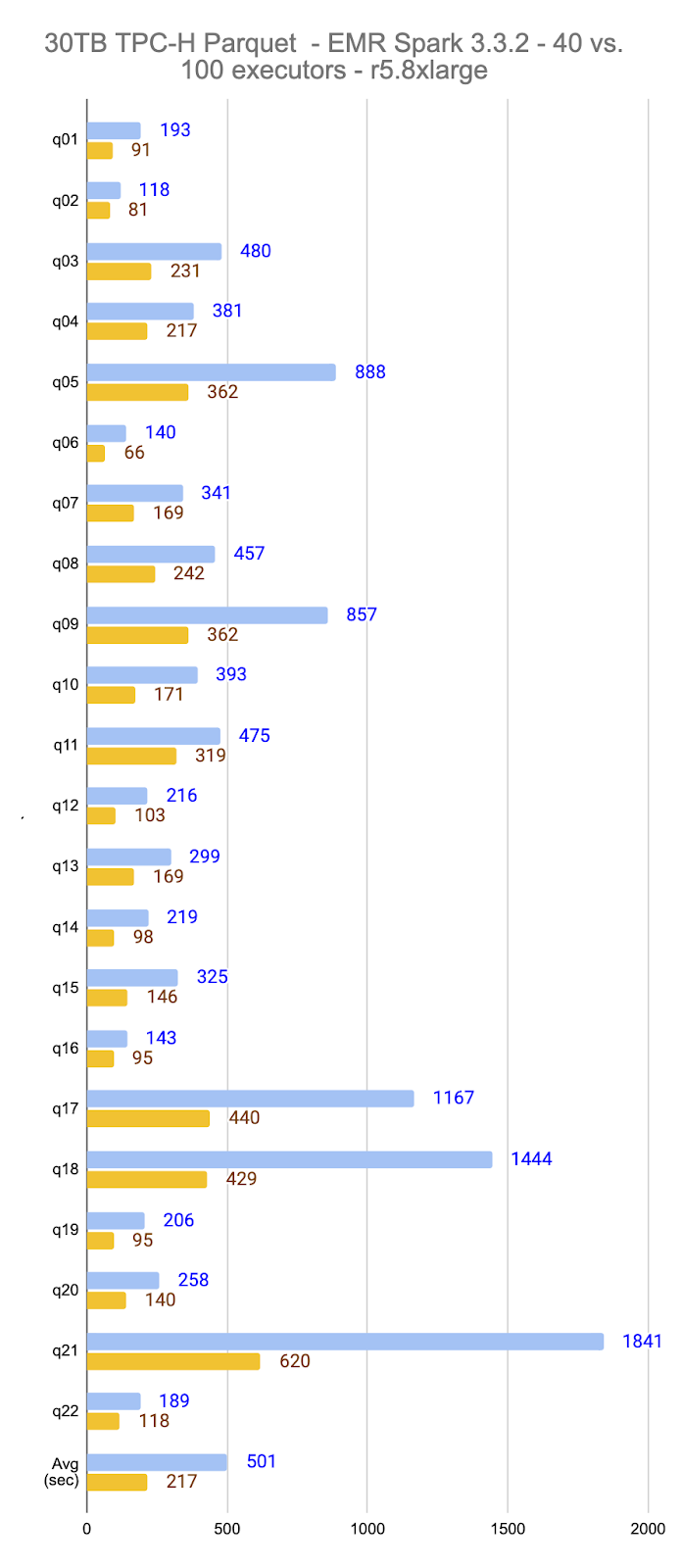
The table below displays the individual query execution times, in seconds, per scenario:
| QID | 10TB - 40 executors |
10TB - 100 executors |
30TB - 40 executors |
30TB - 100 executors |
|---|---|---|---|---|
| q01 | 108 | 62 | 193 | 91 |
| q02 | 62 | 51 | 118 | 81 |
| q03 | 140 | 70 | 480 | 231 |
| q04 | 208 | 120 | 381 | 217 |
| q05 | 246 | 139 | 888 | 362 |
| q06 | 83 | 45 | 140 | 66 |
| q07 | 137 | 84 | 341 | 169 |
| q08 | 184 | 97 | 457 | 242 |
| q09 | 275 | 139 | 857 | 362 |
| q10 | 143 | 76 | 393 | 171 |
| q11 | 116 | 109 | 475 | 319 |
| q12 | 94 | 64 | 216 | 103 |
| q13 | 125 | 78 | 299 | 169 |
| q14 | 91 | 56 | 219 | 98 |
| q15 | 163 | 82 | 325 | 146 |
| q16 | 58 | 50 | 143 | 95 |
| q17 | 254 | 149 | 1167 | 440 |
| q18 | 245 | 148 | 1444 | 429 |
| q19 | 114 | 62 | 206 | 95 |
| q20 | 118 | 68 | 258 | 140 |
| q21 | 439 | 233 | 1841 | 620 |
| q22 | 75 | 57 | 189 | 118 |
| Average | 158 | 93 | 501 | 217 |
| Total (mins) | 58 | 34 | 184 | 79 |
Below is a comparison between the total average execution time in each scenario, relative to other scenarios:
| relative to: | ||||
|---|---|---|---|---|
| 10TB - 40 executors | 10TB - 100 executors | 30TB - 40 executors | 30TB - 100 executors | |
| 10TB - 40 executors | N/A | 171% | 32% | 73% |
| 10TB - 100 executors | 59% | N/A | 18% | 43% |
| 30TB - 40 executors | 317% | 541% | N/A | 232% |
| 30TB - 100 executors | 137% | 234% | 43% | N/A |
AWS Cost Analysis
The following tables compare the cost of running a cluster consisting of 40 executors + 1 coordinator as well as 100 executors + 1 coordinator and the default EMR configuration consisting of 512 GB of gp2 EBS storage per node, in the N. Virginia region.
40 executors + 1 coordinator:
| Component | Price Dimension | Usage | Hourly Cost | Monthly Cost | |
|---|---|---|---|---|---|
| Data store | S3 Standard Storage | 2.7TB (Parquet 10TB) + 7.8TB (Parquet 30TB) = 10.5TB | $0.34 | $242 | |
| Coordinator Node | EC2 Compute | 1 r5.8xlarge instance | $2.02 | $1,452 | |
| Executor Nodes | EC2 Compute | 40 r5.8xlarge instances | $80.64 | $58,061 | |
| EMR Fee - Coordinator | $0.27/hr (r5.8xlarge) | 1 r5.8xlarge instance | $0.27 | $194 | |
| EMR Fee - Executors | $0.27/hr (r5.8xlarge) | 40 r5.8xlarge instances | $10.80 | $7,776 | |
| Hive Metastore | EC2 Compute + EMR fee | 1 m4.large | $0.12 | $86 | |
| RDS MySQL | Hive Metastore storage | 1 db.t3.medium | $0.07 | $49 | |
| EBS Storage | EBS Volume Usage - gp2 | 512GB x 41 = 20992GB | $2.92 | $2,099 | |
| Data Transfer | S3 to EC2 - Intraregional Data Transfer | N/A | $0.00 | $0.00 | |
| Total | $97.16 | $69,959 |
100 executors + 1 coordinator:
| Component | Price Dimension | Usage | Hourly Cost | Monthly Cost | |
|---|---|---|---|---|---|
| Data store | S3 Standard Storage | 2.7TB (Parquet 10TB) + 7.8TB (Parquet 30TB) = 10.5TB | $0.34 | $242 | |
| Coordinator Node | EC2 Compute | 1 r5.8xlarge instance | $2.02 | $1,452 | |
| Executor Nodes | EC2 Compute | 100 r5.8xlarge instances | $201.60 | $145,152 | |
| EMR Fee - Coordinator | $0.27/hr (r5.8xlarge) | 1 r5.8xlarge instance | $0.27 | $194 | |
| EMR Fee - Executors | $0.27/hr (r5.8xlarge) | 100 r5.8xlarge instances | $27.00 | $19,440 | |
| Hive Metastore | EC2 Compute + EMR fee | 1 m4.large | $0.12 | $86 | |
| RDS MySQL | Hive Metastore storage | 1 db.t3.medium | $0.07 | $49 | |
| EBS Storage | EBS Volume Usage - gp2 | 512GB x 101 = 51712GB | $7.18 | $5,171 | |
| Data Transfer | S3 to EC2 - Intraregional Data Transfer | N/A | $0.00 | $0 | |
| Total | $238.59 | $171,786 |
30TB tests had a different EBS configuration compared to the 10TB tests. Instead of 512GB gp2 EBS storage per node: 1,000 GB gp3 storage, 3,000 IOPS and 512 MB/s throughput.
| Storage | IOPS | Throughput | |||
|---|---|---|---|---|---|
| Cluster Size | 1,000 GB | 3,000 | 512 MB/s | Total / month | Delta vs.default EBS configuration |
| 40 executors + 1 coordinator | $3,280 | $615 | $840 | $4,735 | $2,635 |
| 100 executors + 1 coordinator | $8,080 | $1,515 | $2,068 | $11,663 | $6,492 |
It is important to mention that intra-regional Data Transfer was zero, since all components were launched in the same AWS region and VPC subnet, otherwise there would be significant data transfer incurred, which would likely result in hundreds of dollars per each TPC-H test set.
The always-on pricing is for illustration purposes only, since the recommendation is to dynamically scale in and out based on usage.
Below you can visualize how the hourly cost for a particular cluster size (i.e. 40 vs. 100 executors) had an impact on the total execution time for each dataset size.
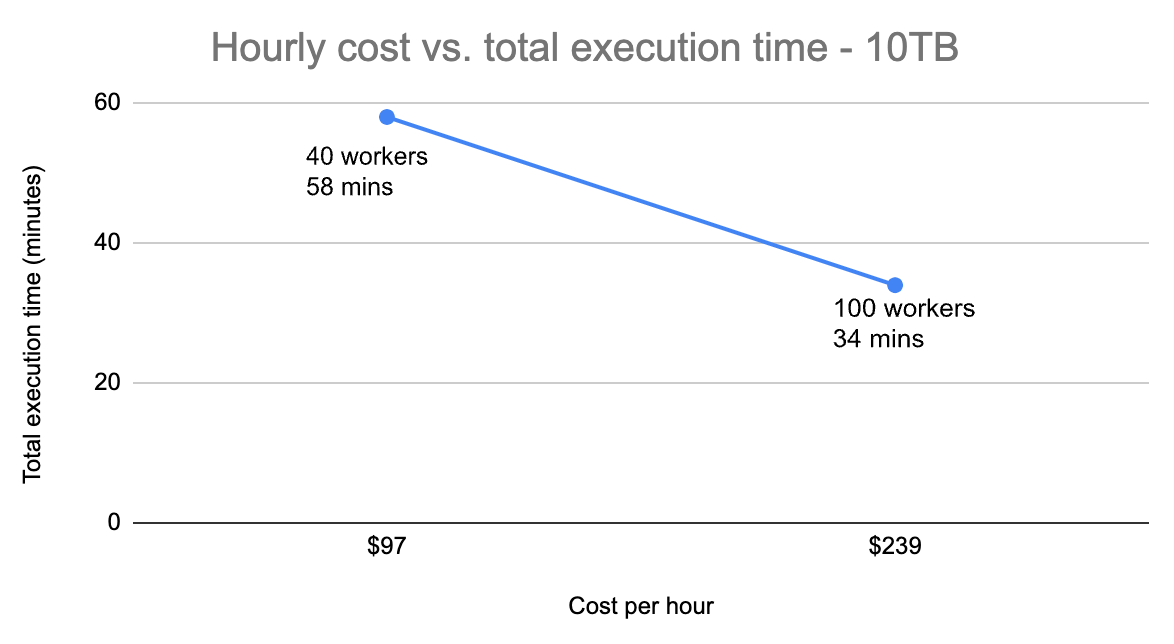
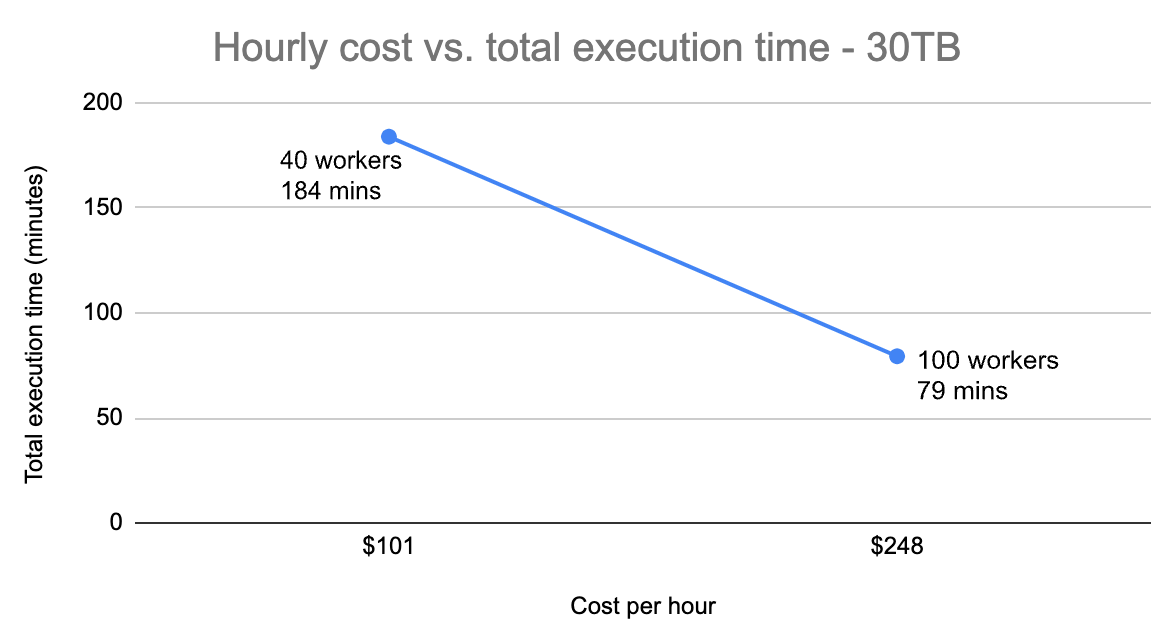
For these tests, it can be seen that a larger cluster size had a more significant impact on how long the whole set of queries took to execute, as the dataset increased (i.e. a higher hourly cost had a better return on the 30TB dataset vs. 10TB)
AWS Cost Management Recommendations
- Use the EMR Managed Scaling feature in order to automatically resize clusters based on usage. Leaving an always-on large cluster will definitely result in thousands of dollars every month in EC2 and EMR cost. Dynamic scaling can significantly lower AWS cost by allocating capacity based on usage patterns.
- Using automation tools, such as the AWS CLI or SDK, significantly simplifies the launch and management of EMR clusters, which can be used to implement custom, automated processes to reduce cost.
- Consider using EMR automatic cluster termination after a configurable idle period, in order to avoid situations where large clusters are accidentally left running for an unnecessary amount of time.
- EC2 Spot Instances are a good option to consider in order to reduce cost, given they can save up to 90% compared to EC2 On Demand pricing. Be aware that Spot instances can be terminated at any point in time; therefore it’s important to ensure they’re used to execute fault-tolerant, asynchronous data analytics processes.
- Allocate storage (S3) and compute resources in the same AWS region, in order to avoid inter-regional data transfer fees between S3 and EC2. Most inter-regional data transfer fees within the US result in $20 per TB, but there are regions outside the US where it can cost as high as $147 per TB (e.g. Cape Town), which would result in several thousands of dollars of additional data transfer cost for the datasets included in these tests. In addition to increased cost, having data and compute resources in different AWS regions can have a significant negative impact on performance, especially in large datasets.
- If there are no strict availability requirements, deploying all EC2 instances in the same VPC subnet can also reduce cost, given that Intra-regional Data Transfer In and Out costs $10 USD per terabyte of data transferred. For a large dataset, such as the one used for these tests, intra-regional data transfer can result in hundreds of dollars, depending on the number and type of queries being executed. For always-on applications with strict availability requirements, it is important to consider deployments in multiple AZs, but it is highly recommended to calculate cost in advance in order to avoid unexpected data transfer charges.
- Once the usage patterns are predictable, it is highly recommended to purchase Reserved Instances. You can refer to this article I wrote, which details how to approach Reserved Instances in the context of EMR workloads.
Conclusions
- EMR Spark successfully executed the full set of 22 TPC-H queries in both datasets (10TB and 30TB).
- Queries showed consistent execution timings across all 3 sequential executions.
- It is always recommended to use automation tools, such as the AWS CLI, SDK or CloudFormation, to launch and manage EMR clusters.
- The average execution time does not necessarily increase proportionally to the size of the dataset. For example: 30TB with 40 executors took 3.17x to execute compared to 10TB with the same number of executor nodes. However, 30TB with 100 executors took 2.34x to execute compared to 10TB and 100 executor nodes.
- Adding more nodes, in this case, resulted in better scalability when increasing the size of the dataset.
- It is important to measure performance and calculate cost on larger datasets as the number of nodes is increased. There are situations where adding more nodes for larger datasets has a positive return on the overall query performance (potentially delivering cost savings). However, there is a point where higher cost might stop delivering proportionally better performance. Therefore, it’s important to execute tests with multiple cluster sizes and measure performance accordingly, in order to find the best cost/performance ratio for a particular application.
Do you need help optimizing your Big Data workloads in the cloud?
I can help you optimize your Big Data workloads in the cloud and make sure they deliver the right balance between performance and cost for your business. Click on the button below to schedule a free consultation or use the contact form.
