
You’re building a new application or migrating an existing application to the cloud. If you’re considering AWS, you want to pick the right components to power your application.
But before you start drawing nice AWS architecture diagrams, it’s very important that you follow the steps described in this article.
With more than 200 services available today, how do you choose an AWS service with confidence? How do you identify advantages and disadvantages of a particular AWS service? How do you know if a particular service will support all the permission scenarios your application requires? How do you know it will integrate nicely with other applications running in a particular AWS region? Is a particular AWS service even available in your AWS region? Do you know how does AWS pricing work for this service? Will it handle your application’s failure scenarios and future growth?
Those are questions you want to answer as early as possible, before you start designing or coding anything. Choosing the right AWS services gets you one step closer to running reliable applications that don’t put at risk your business revenue.
So let’s get started…
Business First
This is the most important step in the whole process. Before you choose any AWS service, you should know how it will impact your business. I recommend to start with the following:
- What are the business flows this application will support? (i.e. submit order, customer sign-up, etc.)
- Who executes those business flows and where from? (i.e. customers, other systems)
- What is the frequency of each business flow? (i.e. 1000 orders per hour, 100 sign-ups per hour, etc.)
- What will happen to your business -in quantifiable terms, such as lost revenue or number of negative mentions- if any of these flows stops working for: 1 minute, 5 minutes, 1 hour, 8 hours, 24 hours?
Having answers to those questions will give you the right context to make important system decisions.
AWS Regions
Not all services are available in all AWS regions. Some services take a long time before they’re released in certain regions (like 500 days or more in some cases, if they become available at all).
- Make sure the service you’re considering is available in your chosen AWS region.
- Evaluate the cost of all services your are considering in all AWS regions. Depending on the AWS region, some price dimensions can cost as much as 177% more, compared to the cheapest region (i.e. outbound internet data transfer in Sao Paulo vs. N. Virginia).
- For a more complete analysis on AWS regions, take a look at this article.
Performance and Scalability
One of the most expensive errors often made is ignoring performance and scalability from day-1 of design. Your application will eventually grow (that’s the whole point of building things, right?) and you don’t want to find the limits of a particular application or AWS configuration when your customers are frustrated by slow times or frequent outages.
To avoid expensive and embarrassing situations, I recommend you evaluate the following:
Service limits
AWS sometimes seems like this infinite source of computing power, but there are limits. Particularly limits applied to your account.
Here are examples of some service limit dimensions:
- Number of provisioned resources (i.e. EC2 instances, SQS queues, CloudWatch Alarms, IAM Roles/Users, S3 Buckets, VPCs)
- Data retention periods (i.e. CloudWatch metrics, Kinesis streams, SQS message retention)
- Throughput (i.e. concurrent Lambda executions, CloudWatch List/Describe/Put requests, SNS messages per second, Dynamo DB capacity units, EFS throughput in Gb/s)
- Payload size (i.e. SQS messages, Dynamo DB items, Kinesis records, IoT messages, IAM policy size)
- Storage size (i.e. EBS volume size)
Note that some limits can be increased (for example, number of EC2 instances you can launch), while others cannot (for example, metric retention in CloudWatch). Make sure there are no deal breakers for your application in the “cannot be increased” category.
Here is a complete list of AWS Service Limits
What can be scaled in that particular AWS service
When evaluating a particular service, I recommend identifying those AWS resources or configurations that drive scale for your applications. This will allow you to start with the right capacity for each AWS service and have a strategy in place to scale your AWS components as your application’s usage grows.
Examples: provisioned EC2 instances, Dynamo DB capacity units, Lambda function concurrency, RDS read replicas, Elastic Load Balancers, ElastiCache cluster size.
Who does the scaling for that AWS service and how?
Once you identify the AWS resources and configurations that drive scale, you have to identify WHO does the scaling and HOW it is done, so you can have a solid strategy in place. I’ve identified the following categories:
- Customer does the scaling. There are mechanisms to increase scale, but they have to be triggered
explicitly by you.
- Examples: DynamoDB capacity units (if not using DynamoDB Auto Scaling), Kinesis number of shards, EC2 instance types, RDS read replicas, RDS storage increase, AWS Elasticsearch node count.
- AWS does the scaling. You don’t have to worry about managing scale at all.
- Examples: Lambda function executions, S3 bucket size and number of objects, Dynamo DB table size, SQS messages per second
- Shared responsibility. AWS offers automated mechanisms, but you have to configure them.
- Examples: EC2/ECS Auto Scaling, Elastic Load Balancer (configuration and pre-warming), DynamoDB Auto Scaling, RDS Aurora Read Replica Auto Scaling.
Scaling scenarios for the service under review
Once you identify the scaling mechanisms for a particular AWS service, I also recommend to evaluate and to design scaling strategies for the following usage scenarios:
- Low usage. How are you going to ensure that the AWS service under review is not over-provisioned during periods of low usage (i.e. at night or weekends, for some applications).
- Steady growth. How is the service going to handle a gradual growth in usage over time.
- Spikes. How is the service going to handle sudden spikes in usage, such as 1x, 3x, 5x, 10x.
After you identify how to manage scale, the next step is to include scaling strategies into your architecture and application design and implementation, as well as your capacity planning.
Availability
AWS has an army of extremely talented engineers ready to prevent and resolve all sorts of failure scenarios. However, failures in the AWS service under review will occur from time to time. If you want to minimize the risk of lost revenue for your business, you have to consider the options a particular AWS service gives you in order to handle failure. It’s also worth considering how difficult it is to set up those mechanisms.
Failure scenarios (what can go wrong)
Here are some high level categories of error situations you might encounter for a particular AWS service:
- Failure to access existing AWS resources.
- Examples: cannot describe EC2 instances, GET API failures and elevated latencies
- Failure to create new AWS resources.
- Examples: increased errors and increased latency when launching EC2 instances
- Connectivity failure inside and between Availability Zones.
- Examples: increased errors and latency between RDS master and read replicas, connectivity errors and increased latency between EC2 instances in the same, or different, AZs.
I highly recommend assessing the common error scenarios for a particular service and start the design of your failure recovery strategies from there. A great starting point is going to the AWS Service Health Dashboard page and taking a look at the status history for a particular service, in all AWS regions. This will give you an idea of the type of failures that have occurred in the past.
Redundancy options
Redundancy is having extra AWS resources that will take over, in case of failure.
Examples: having extra EC2 instances ready to immediately take traffic in case of failure, data replication in S3, Dynamo DB cross-region data replication, RDS read replicas.
Consider:
- AWS Cost (remember price varies significantly between AWS regions)
- Is it built into this AWS service, or do I have to implement it?
- If you have to implement it, how expensive will it be to do so?
Failover mechanisms
Failover mechanisms are the systems in place to bring those redundant AWS resources online.
Examples: Route 53 DNS failover that sends traffic to a backup region, EC2 Auto Scaling, ELB Health Checks.
Similarly to Redundancy options, evaluate if Failover mechanisms are built into AWS or if you have to implement them yourself, as well as the cost of doing so.
Authentication, Authorization and Auditing
AWS has multiple mechanisms to give you control and to ensure your AWS resources and data are accessed and stored securely. Identity and Access Management is the central and global mechanism for authentication and permissions management in AWS. There are, however, additional mechanisms and tools that vary by service.
Resource-based policies
A resource-based policy is assigned to a specific AWS resource, such as an S3 bucket, SNS topic or SQS queue. This type of policy declares specific AWS accounts that can access that resource and the operations that can be executed against it.
Resource-based policies are different from IAM Roles and provide a different model by which you can grant a third-party access to your AWS resources. Not all AWS services support resource-based policies, therefore it’s relevant to see if a particular service supports them.
For more on resource-based policies, click here.
CloudTrail support
CloudTrail is AWS auditing mechanism. It aggregates API activity for your AWS services, giving you information such as: API operation, who called it, when, where from and many other pieces of data.
While CloudTrail supports most, if not all, AWS services, it doesn’t necessarily support all API operations for a particular AWS service. Therefore, it is important to evaluate which operations will be available in CloudTrail for the AWS service you’re considering.
For more on supported services by CloudTrail, click here.
Encryption at rest
AWS has been gradually introducing encryption at rest for many services, including S3, EBS, Glacier, EMR, RDS, Redshift and DynamoDB. When assessing a particular AWS service, I recommend you consider the different options you get for encrypting data at rest, including using Key Management Service.
The following AWS whitepaper has good information on alternatives for encrypting data at rest (it’s a bit dated, but still has good information).
Supported programming languages
AWS offers a wide range of programming languages in its Software Development Kits (SDKs) and all services are included in each SDK package. However, not all application code is implemented using SDKs.
Some examples:
- API Gateway generates client SDKs for Javascript, Android and iOS clients.
- Lambda functions can only be written in Python, NodeJS, Java, C# and Go.
- Simple Workflow (SWF) only offers the Flow framework in Java and Ruby.
My recommendation is that you look beyond the SDK and make sure all code components in your application are supported by the AWS service you’re evaluating.
Integration with other AWS services
If you’re evaluating a particular AWS service, most likely you won’t use that service in isolation. You will have other architecture components, implemented using other AWS services, talking to each other.
I recommend that when evaluating a particular AWS service, you take a look at how easily you can integrate it with other services.
AWS built-in integrations
This is one of the coolest trends I’ve seen in AWS. There is a growing number of features that make AWS service integrations very simple. These features often deliver “out of the box”, event-driven functionality that would have taken customers a lot of work to develop and operate.
Here are some examples:
| Origin | Target |
|---|---|
| CloudWatch Events | Lambda, SNS, SQS, Kinesis |
| CloudWatch Logs Subscriptions | Kinesis, Lambda |
| S3 Events | SNS, SQS, Lambda |
| Dynamo DB streams | Kinesis, Lambda |
| Kinesis | Lambda |
| IoT | CloudWatch Alarms and Metrics, DynamoDB, Elasticsearch, Kinesis, Lambda, S3, SNS, SQS |
| CloudWatch Alarms | EC2 Actions, SNS |
| EC2 | CloudWatch Events |
| KMS | CloudWatch Events |
| SES | Lambda |
| Cognito | Lambda |
| CloudFormation | Lambda |
| API Gateway | Lambda |
| SQS | Lambda |
| CodeDeploy | CloudWatch Events |
| Auto Scaling | CloudWatch Events, SNS |
A common pattern here is that most integrations include AWS Lambda, which is great because Lambda functions give you the flexibility to implement custom code in response to those events.
Custom integrations
If you have any AWS cross-service integrations that are not built-in, then this is a good time to identify them and think about the effort it will take to implement them.
Available services in your chosen AWS region
Keep in mind that not all services are available in all regions. When you evaluate a particular AWS service and its integrations (built-in or not), it will be much easier if all involved AWS services are available in the same region.
Operations - Monitoring
Early design of operational procedures is extremely valuable. If you’re considering a particular AWS service, evaluating its features in this area will help you identify architecture and application components that will make your operations easier. The earlier you do this, the better. Since monitoring is an essential part of operational procedures, I highly recommend knowing which metrics are available for a particular AWS service.
Available CloudWatch metrics
CloudWatch is AWS metric aggregation service. All AWS services publish metrics to CloudWatch, which let you monitor system health and take action when things are not going as expected.
Here is the official list of supported CloudWatch metrics and dimensions.
In addition to metrics and dimensions, it is important to understand how often metrics are published (1-minute or 5-minute intervals). For example, while API Gateway publishes metrics every minute, EMR does so every 5 minutes. EC2 gives you the option to publish 1-minute metrics at an additional cost. Make sure metric intervals make sense for your application.
Consider using CloudWatch features such as dashboards, metric percentiles, metric math and metric filters.
Missing CloudWatch metrics
The next natural step is to identify which metrics are NOT available in CloudWatch for a particular service, so you can design a strategy to capture all those additional metrics. For example, CloudWatch doesn’t publish metrics for memory or disk utilization in an EC2 instance.
Once you identify which metrics are not available in CloudWatch, a good alternative is to look into third-party products like New Relic, DataDog or open source solutions, such as collectd. You can also implement your own custom metrics.
In any case, identifying metric collection strategies should be part of any AWS service assessment.
Operations - Incident management
The main question to answer in this section is: “if I use this particular AWS service, how easy will it be to deal with incidents?”
Alarms and Notifications
All CloudWatch alarms have the option to trigger an SNS notification. But once CloudWatch sends a notification to SNS, you have a number of options, such as calling an HTTP/HTTPS endpoint (useful for 3rd party tools such as PagerDuty or VictorOps), invoking a Lambda function, sending a message to an SQS queue or sending an e-mail.
Some questions to ask are: if you use this AWS service, how will you know when something is not right? Are the existing metrics for this service enough to create a meaningful alarm? Are 1-minute or 5-minute data points the right window to determine if an alarm should be triggered? Do you need something more responsive than that? Once a CloudWatch Alarm triggers an SNS notification, are my existing mechanisms enough to initiate prompt and effective remediation? Do I need to create/adapt response mechanisms if I use this particular AWS service?
Automatic remediation
Based on the failure scenarios you have identified earlier, the main question here is: “if I choose this AWS service, how can I fix issues automatically ?”
Consider options such as Auto Scaling, EC2 Actions (Recover, Reboot), Lambda functions or custom remediation processes that can be triggered after an alarm is notified to SNS.
Operations - deployment and management
An often overlooked aspect when evaluating an AWS service is deployment automation. How are you going to automate setup and deployments to applications that are powered by this service?
Using CloudFormation
CloudFormation is one of those AWS services that can save you a lot of pain and hours (even days) of manual, tedious work. Using CloudFormation you can define your AWS infrastructure components and configuration using JSON or YAML templates. CloudFormation interprets these templates and orchestrates the creation and configuration of AWS resources. It does have a learning curve and it takes some time to get started - but once you create your first templates, it delivers great returns.
Even though most (if not all) AWS services and resource types are supported by CloudFormation, it’s always a good practice to double check. I recommend taking a look at CloudFormation’s documentation and making sure it supports the AWS service you are considering and the resource types you need.
It’s also important to identify any automated processes that you need to run before, during or after resource creation for the AWS service under assessment.
AWS Deployment Automation options
AWS offers a number of services geared towards deployment automation: CodeBuild, CodeDeploy, Code Pipeline, Elastic Beanstalk, OpsWorks. If none of these AWS services are a good fit, then it’s a good idea to evaluate third-party tools such as Ansible, Chef or Puppet.
Deployment rollback
How can you execute deployment rollbacks in this service? For example, can you use Route 53 or ELB do to Blue/Green deployments? In the case of Lambda, versions and aliases are a great option for code rollbacks. How quickly (from incident detection to resolution) can you rollback code if your application uses a particular AWS service?
Automation using CloudWatch Events
CloudWatch Events is a great AWS service that allows you to create rules that get automatically triggered based on pre-configured conditions (i.e. schedules, starting an EC2 instance, calling an API, Auto Scaling life cycle events, etc.) You can then do something as a response to those events, such as executing a Lambda function or sending a message to an SQS queue, or SNS notification.
The question here is: “can you use CloudWatch Events with this service?”
Level of commitment from your application’s design and code (will my application be “locked-in”?)
Whether you’re building a new application or migrating an existing one to AWS, there will be design and coding considerations your application has to follow before you can use a particular AWS service.
There are some AWS services that you can use without doing any design or code updates. But there are some services that are deeply embedded into how you design and implement your application. The more your design and code is geared towards a particular AWS service, the more difficult it will be come to migrate your application out of AWS (a.k.a “lock-in”). Given the advantages that many AWS services offer, this is a very reasonable trade-off, but you should be aware of it.
I’ve identified the following categories:
- No, or minimal, design or code considerations - just configure AWS components. Examples: CloudFront, Route 53, EC2, RDS, CloudWatch(built-in metrics), CloudFormation, Route 53, CloudWatch Logs
- Design considerations are required, but there are no AWS APIs required in your application code. As long as your design is compatible, all you have to do is configure the AWS service. Examples: Auto Scaling, ELB, VPC, EMR.
- General design considerations and AWS APIs are required in your application code. Examples: S3, SQS, CloudWatch (custom metrics), ElastiCache, SNS.
- Fundamental design and code considerations. Your application is designed and built, from day-1, for these services. Examples: Lambda, Dynamo DB, Simple Workflow, IoT, Kinesis
The level of lock-in will vary depending on your application and destination, but the following diagram shows a general starting point:
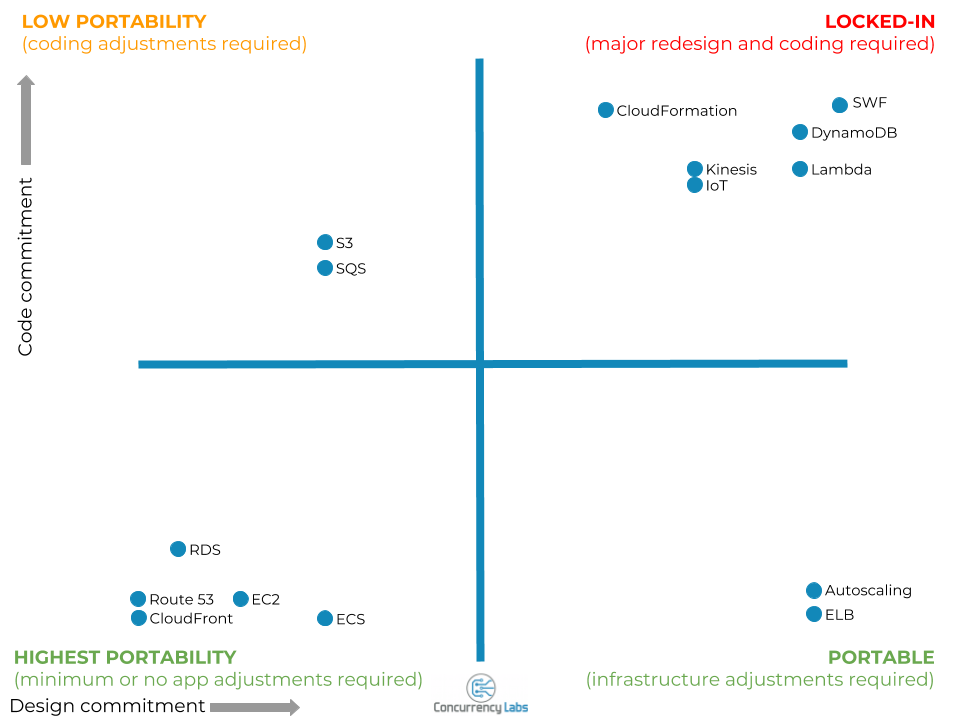
In addition to design and code implications, you should consider the cost of eventually migrating your data OUT of AWS. For example, transferring 1 PB of data out of S3 would cost you around $55K, while 100TB would cost approximately $8K. Most likely you would have to use AWS Snowball, or a lot of parallel processes on your end (unless you want to spend months exporting your data).
Migration
If you’re migrating an existing application to AWS, you will need a detailed migration plan with very specific steps. Although AWS migration steps are beyond the scope of this article, I recommend you consider the following, when evaluating an AWS service:
Application updates required for migrating to AWS
Will your application require significant updates to both design and application code? How significant are those changes? Is a migration as simple as just deploying your code on EC2 and configuring your AWS infrastructure? Do you even have to deploy application code? Take a look at the Lock-in diagram in this article for some examples.
AWS migration tools for the service under review
If you’ll be migrating an existing application, see if there are AWS services that can help. Some examples are:
- AWS Server Migration Service.
- AWS Database Migration Service.
- AWS Schema Conversion Tool.
- AWS Management Portal for vCenter.
- AWS Data Pipeline.
- AWS Storage Gateway.
- AWS Direct Connect.
- AWS S3 Transfer Acceleration.
- AWS Kinesis Firehose.
- AWS Direct Connect.
Cost
Identify AWS price dimensions relevant to your application and AWS service
It is common to see some AWS customers ignoring very important price dimensions for their applications. For example, estimating EC2 cost only based on instance types and ignoring data transfer or storage.
Let’s say you’re running a file server using a t2.Large instance and you only focus on hourly compute charges for that instance type. The compute charges for one t2.Large instance would be around $68/month in N. Virginia. But if your application transfers 1 TB/ month out to the internet, you would pay $90/month on data transfer alone. 1 TB of EBS SSD storage (gp2) would cost you $100/month.
Make this mistake at scale and you’re looking at thousands of dollars in unforeseen cost per month for your chosen AWS service.
Calculate price at scale
You build applications with success in mind, right? When evaluating an AWS service, I recommend that you calculate pricing for low and high usage of your application.
Some AWS services cost less when usage grows. One example is S3 storage, which has different price brackets depending on usage.
In a previous article about operating Lambda functions, I pointed out that a particular Lambda function can be more expensive at 100TPS compared to a cluster consisting of 10 M3.large EC2 instances. The example I gave includes a function that consumes 1000ms and requires 512MB of memory in each execution. The price difference is $14,500 per year. If this function had low volume, Lambda would be a clear winner in terms of cost.
Compare pricing in ALL AWS Regions for a particular AWS service
Not all AWS services cost the same in all regions. There are cases with extreme price differences. When evaluating an AWS service, I recommend considering not only service availability in a particular region, but also cost.
For example, 1TB of EC2 data transfer out to the internet costs $250 in Sao Paulo, compared to $90 in N. Virginia (a 177% difference!)
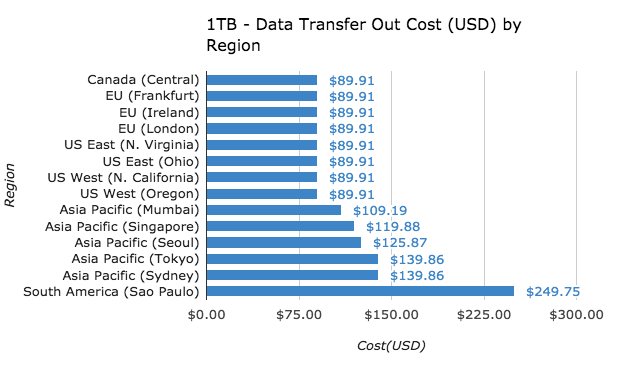
Or take a t2.large EC2 instance. If you launched one in Sao Paolo, you would pay 60% more compared to N. Virginia. If you thought N. California would be the same price as N. Virginia, you would actually pay 19% more.
I wrote this article where I take a look at key differences in AWS regions.
Training
Skill Gaps Assessment
At some point, someone will have to work with the AWS service under review. There are three main areas to identify: 1)Current AWS knowledge in your team, 2)Required knowledge, 3)How to address knowledge gaps.
Regarding required knowledge, consider areas you’ll need for each of the sections covered in this article: AWS fundamentals (regions, Availability zones, available services, etc.), the AWS service under evaluation, IAM and other AWS security services (CloudTrail, Inspector, WAF, Cloud HSM, KMS, etc.), AWS services your application will integrate with, operations and deployment in AWS, cost management in AWS as well as migrating to AWS.
You can address gaps through training, hiring, or by partnering with an AWS expert.
Here is an article I wrote with some tips on what to look for when hiring cloud engineers.
Considering alternatives
So, you analyzed a lot of factors and are not convinced a particular AWS service is a good fit. What to do next?
EC2-hosted alternatives to AWS-managed services
This is not my favorite option, but sometimes it’s a valid one.
Let’s say you’re evaluating Dynamo DB or SQS, which are services 100% managed by AWS. It might be the case that you a find a deal breaker for your application and decide these services are not a good fit. One last step is to consider EC2-hosted alternatives. For example, Cassandra or MongoDB running on EC2. Or RabbitMQ running on EC2 instead of SQS. Perhaps Kafka running on EC2 instead of Kinesis.
I always recommend evaluating AWS-managed services first, since I really like to avoid managing infrastructure. But there are valid cases where an EC2-hosted solution could be a better alternative.
What if an AWS service is not the best option?
After you take a look at all relevant factors, it might be the case that AWS doesn’t offer the best solution for your application. Comparing other cloud providers or on-premise alternatives is beyond the scope of this article, but I encourage you to consider all options. At the end of the day, you want to make the most informed decision.
Just make sure that when evaluating other services, you consider the same factors that you did for AWS.
Create a cloud implementation plan
Evaluating a particular AWS service is just the beginning. I recommend following the steps in this article each time you’re designing or migrating an application. Each case is different and just because a particular AWS service was a good fit for previous implementations, doesn’t mean it will be for your next application.
After you’ve evaluated an AWS service, most likely you’ll find gaps and areas that need to be addressed. All these gaps should be action items in your cloud implementation plan or backlog.
Conclusions
- Whether you’re designing, building or migrating an application, you should know as early as possible which AWS services it’s going to use and be sure they’re a good fit.
- I highly recommend that you follow a systematic approach when evaluating AWS services. The number of services and variables to look at make it very easy to make critical mistakes.
- These are the areas I recommend to focus on when evaluating a particular AWS service:
- Identify and measure the business flows your systems and AWS services will support.
- Programming language restrictions.
- Which AWS region you’ll choose for this AWS service.
- Service limits, latency and how are you going to scale your application using this AWS service.
- Failure scenarios for that AWS service as well as redundancy options and failover mechanisms.
- Authentication, authorization, auditing and encryption options for this AWS service.
- How that AWS service integrates with other AWS services (built-in and custom integrations) and which AWS services are available to integrate with in the AWS region you’ve chosen.
- If you choose that AWS service, how are you going to monitor your application (built-in and custom metrics).
- If you choose that AWS service, how are you going to operate your application (alarms, notifications,
automatic remediation). - What deployment automation options are available for that AWS service.
- How easy it is to automate other processes if you choose that AWS service.
- Level of lock-in for that AWS service
- Cost at different levels of usage (low to high).
- Migration options for that AWS service.
Do you need help with choosing the right AWS services for your applications?
I’d be glad to hear about it in a FREE 30-minute consultation. I can certainly help you have a successful product launch. Just click on the button below to schedule one. Or send me a message using the contact form.
