
** Price calculations using AWS Price List API
AWS Lambda is the leading product when it comes to Serverless computing, or Function as a Service (FaaS). With AWS Lambda, computing infrastructure is entirely managed by AWS, meaning developers can write code and immediately upload and run it in the cloud, without launching EC2 instances or any type of explicit compute infrastructure.
This is a great thing, as it brings a lot of agility to product development. However, running a reliable Lambda application in production requires you to still follow operational best practices. In this article I am including some recommendations, based on my experience with operations in general as well as working with AWS Lambda.
Let’s start with what I see as the #1 rule for AWS Lambda…
Just because AWS manages compute infrastructure for you, doesn’t mean Lambda is hands-off.
I’ve heard and read many comments that suggest Lambda releases developers from the burden of doing operational work. It doesn’t. Using AWS Lambda only means you don’t have to launch, scale and maintain EC2 infrastructure to run your code in AWS (which is great). But essentially everything else regarding operations remains the same, just packaged differently. Running an application on AWS Lambda that reliably generates revenue for your business requires the same amount of operational discipline as any other software application.
… and here are some recommendations:
Monitor CloudWatch Lambda metrics
Here are some relevant Lambda metrics available in CloudWatch:
- Duration. This number is rounded up to the nearest millisecond. The longer the execution, the more you will pay. You also have to make sure this metric is not running dangerously close to the function’s timeout. If this is the case, either find ways for the function to run faster, or increase the function timeout.
- Errors. This metric should be analyzed relative to the Invocations metric. For example, it’s not the same to see 1,000 errors in a function that executes 1 million times a day compared to a function that executes 10,000 times a day. Is your application’s acceptable error rate 1%, 5% or 10% within a period of time? The good news is that CloudWatch supports metric math (i.e. Errors/Invocations), therefore you can monitor your functions and configure alarms based on error rates. Later in this article, I will cover Lambda’s retry behavior in case of errors.
- Invocations. Use this metric to determine your error tolerance, as mentioned above. Using metric math is very important in order to have an Errors/Invocations ratio. This metric is also good to keep an eye on cost: the more invocations, the more you will pay. In order to forecast pricing, consider not only invocations but also the memory you have allocated to your function, since this impacts the GB-second fee you will pay. Also, when do zero invocations start to tell you there’s something wrong? 5 minutes, 1 hour, 12 hours? I recommend setting up alarms when this number is zero for a period of time. Zero invocations likely means there is a problem with your function’s trigger.
- Throttles. If you expect your overall function executions to be above 1,000 concurrent executions, then submit a limit increase in AWS - or you’ll risk experiencing throttled executions. This should be part of your regular capacity planning. I recommend setting up alarms when the Invocations metric for each function is close to the number you have assigned in your capacity planning exercise. If a particular function is being throttled, that’s obviously bad news, so you should configure CloudWatch alarms based on this metric. Something useful to consider is that you can assign Reserved Concurrency to a particular function. If you have a critical function, you can increase its availability by assigning a Reserved Concurrency value. This way critical functions will not be affected by high concurrency triggered by other less critical functions. Keep in mind this value is different from Provisioned Concurrency, which will be described later in this article.
- DeadLetterErrors. Lambda provides a very useful feature called Dead Letter Queue. This allows you to send the payload from failed asynchronous executions to an SQS queue or SNS topic of your choice, so it can be processed or analyzed later. If for some reason you can’t write to the DLQ, you should know about it. That’s what the DLQ Errors metric tells you. Lambda increments this metric each time a payload can’t be written to the DLQ destination.
- IteratorAge. If you have Lambda functions that process incoming records from either Kinesis or DynamoDB streams, you want to know as soon as possible when records are not processed as quickly as they need to. This metric will help you monitor this situation and prevent your applications from building a dangerous backlog of unprocessed records.
- ConcurrentExecutions. Measures the number of concurrent executions for a particular function. It’s important to monitor this metric and make sure that you’re not running close to the Concurrent Executions limit for your AWS account or for a particular function - and avoid throttled Lambda executions.
- UnreservedConcurrentExecutions. Similarly to the previous metric, only this one allows you to know how close you’re getting to your Lambda concurrency limit in a particular region.
- ProvisionedConcurrencyUtilization. This metric indicates the ratio of Provisioned Concurrency executions vs. the allocated number of Provisioned Concurrency for a particular Lambda function. It tells you how close you’re getting to the number of Provisioned Concurrency for that function.
- ProvisionedConcurrencySpilloverInvocations. In situations where a Lambda function’s executions are higher than the number of Provisioned Concurrency, this metric will show the number of executions above Provisioned Concurrency. Ideally, it should be zero, therefore it’s recommended to trigger an alarm when this value is > 0.
Enable AWS Compute Optimizer
AWS Compute Optimizer is a service that uses AI algorithms to identify potential optimizations in the configurations of AWS compute resources, including Lambda functions. Compute Optimizer findings can include performance (memory) and cost optimizations, therefore it’s a good practice to enable AWS Compute Optimizer and regularly review the potential recommendations found by this service.
Allocate the right memory for your function
Even with AWS Compute Optimizer enabled, it’s still required to perform a proactive optimization analysis. For example, analyzing Lambda execution logs. Do you see anything wrong with this message?
Duration: 799.16 ms Billed Duration: 800 ms Memory Size: 512 MB Max Memory Used: 15 MB Init Duration: 121.75 ms
This log entry is saying that you might be paying for over-provisioned capacity. If your function consistently requires 15MB of memory, you should consider allocating less memory, not 512MB. Here is a price comparison between two configurations, assuming 100 million monthly executions:
| Memory (MB) | 100 million x 800ms |
|---|---|
| 128 | $170 |
| 512 | $682 |
If you think 100 million executions is a large number, you’re right. But once you start using Lambda in a high volume application, for processing CloudTrail records, Kinesis, S3 events, API Gateway and other sources, you will see that executions add up really fast and you’ll easily reach 100 million monthly executions.
If you were using this function at a rate of 100 million executions per month, you would pay approximately $8,184 per year instead of $2,040. That’s money you could use on more valuable things than an over-provisioned Lambda function.
That being said, allocating more memory often means your function will execute faster. This is because AWS allocates more CPU power proportionally to memory size. You can read more details here. If most of your function’s execution time is spent doing local processing (instead of waiting for external components to complete), having more memory will in many cases result in faster executions - and potentially lower cost.
Therefore, my recommendation is to test your function with different memory allocations, then measure execution time and calculate cost at scale. Just make sure the function is already warmed up, so you can measure the right execution time. You can find more details about Lambda function initialization here.
Consider using AWS Lambda Layers, Extensions and Container Images
Lambda Layers is a feature that can simplify the management of code packages that go into a Lambda function. They simplify the build process, since common code components can be made available to multiple functions as a Lambda Layer. Like any other dependencies, it has to be treated with caution, since updates to Layers can potentially affect multiple applications. That being said, Layers can simplify the rollout and operations of Lambda functions significantly.
Lambda Extensions are processes that run in addition to the Lambda function execution. They can run as an internal or external process, depending on how they’re declared. Internal extensions run together with the function invocation process, while external extensions run independently of the Lambda function invocation. They’re both a useful way to add functionality to a Lambda function before, during or after its execution.
Typically, Lambda functions are deployed using a .zip file with all the code dependencies as well as Lambda Layers. However, there’s also the option to deploy the code for a Lambda function using a Lambda Container Image, which is essentially a Docker image stored in the AWS Elastic Container Repository (ECR). The process involves building a Docker image with the Lambda source code as well as its dependencies and then publishing it in an ECR repository. This Docker image also determines the Lambda runtime that will be assigned to a function.
Lambda Layers, Extensions and Container Images offer a way to potentially simplify the management of code and its dependencies inside a Lambda function. They offer advantages that need to be evaluated on a case-by-case basis before reaching a conclusion on whether they’re a good fit or not for your particular application.
Useful CloudWatch Features
CloudWatch offers a number of features that are particularly useful for Lambda functions. Below, I mention the ones I’ve used in order to operate and optimize Lambda functions.
Metric Filters
The AWS Lambda service automatically writes execution logs to CloudWatch Logs. CloudWatch Logs has a very useful feature called Metric Filters, which allows you to identify text patterns in your logs and automatically convert them to CloudWatch Metrics. This is extremely helpful, so you can easily publish application-level metrics to CloudWatch. For example, every time the text “submit_order” is found in CloudWatch Logs, you could publish a metric called “SubmittedOrders”. You can then create an alarm that gets triggered if this metric crosses a predefined threshold within a period of time.
Something very important about using Metric Filters is that as long as there is a consistent, identifiable pattern in your Lambda function log output, you don’t need to update your function code if you want to publish more custom CloudWatch metrics. All you have to do is configure a new Metric Filter. Even better, Metric Filters are supported in CloudFormation templates, so you can automate their creation and keep track of their history.
CloudWatch Logs Insights
CloudWatch Logs Insights is a great tool you can use to operate your Lambda functions. It offers a powerful query syntax and platform that you can use to filter Lambda logs by timestamp and by text patterns. You can also export your findings to CloudWatch Dashboards or text files for further analysis.
CloudWatch Lambda Insights
CloudWatch Lambda Insights is delivered as a Lambda Layer and it aggregates Lambda metrics in CloudWatch. Iit shows useful information not available in default metrics, such as memory, CPU and network usage as well as initialization duration. It adds more detailed visibility into how a Lambda function performs and it’s a useful way to optimize performance, cost as well as troubleshooting and preventing operational issues.
If you have an environment with a very high number of Lambda functions, I would recommend to not enable this feature in every single function, given that it could potentially increase the overall cost of Lambda in a noticeable way (it’s not uncommon to see deployments that involve literally hundreds of functions across multiple stages). Enabling Lambda Insights results in 8 paid metrics, at $0.30 each one, resulting in a total of $2.4 USD per function. In such a scenario, I would start with the most critical or problematic functions. There’s also a number of additional CW Logs entries when enabling Lambda Insights (approximately 1.1KB per Lambda execution). At $0.50 per GB of ingested log data, this number could become significant for functions with a very high execution volume.
This is definitely a feature worth exploring, which can significantly help with operational tasks of Lambda functions.
CloudWatch Application Insights
This feature is an easy way to monitor, group and discover relevant metrics for your Lambda functions. It works with AWS Resource Groups, which are a way to aggregate metrics for components that can be organized together as part of an application, using tags or common components such as CloudFormation templates. This feature is a quick way to view and discover multiple metrics in a single place before manually creating dashboards (it doesn’t replace the need to create custom CloudWatch Dashboards, though).
When something fails, make sure there is a metric that tells you about it
When it comes to operations, nothing is more dangerous than being blind to errors in your system. Therefore, you should know there are error scenarios in Lambda that don’t result automatically in an Error metric in CloudWatch.
Here are some examples:
- Python. Unhandled Exceptions result automatically in a CloudWatch Error metric. If your code swallows exceptions, there will be no record of it and your function execution will succeed, even if something went wrong. Logging errors using
logger.errorwill only result in an[ERROR]line in CloudWatch Logs and not automatically in a CloudWatch metric, unless you create a Metric Filter in CloudWatch Logs that searches for the text pattern “[ERROR]". - NodeJS. If the function ends with a
callback(error)line or throws an exception, Lambda will automatically report an Error metric to CloudWatch. If you catch an exception and end withconsole.error(), Lambda will only write an error message in CloudWatch Logs and no error metric will be published, unless you configure a Metric Filter in CloudWatch Logs.
You can also use Metric Filters to identify application errors that by design shouldn’t result in a Lambda execution failure (i.e. failed data validations, specific code conditions, etc.)
Know what happens “under the hood” when a Lambda function is executed
AWS uses container technology that assigns resources to each Lambda function. Therefore, each function has its own environment and resources, such as memory and file system. When you execute a Lambda function, two things can happen: 1) a new container is instantiated, 2) an existing container is used for this execution.
You have no control on whether your execution will run on a new container or an existing container. Typically, functions that run in quick succession are executed on an existing container, while sporadic functions need to wait for a new container to be instantiated. Therefore, there is a difference in performance in each scenario. The difference is typically in the milliseconds range but it will vary by function and in many cases it’s noticeable.
Also, it’s important to differentiate between 1) function and 2) function execution. While a function has its own isolated environment (container), multiple function executions can share resources allocated to their respective function. Therefore, it is possible that function executions access each other’s data.
I recommend the following:
- Run a load test for your particular function and measure how long it takes to execute during the first few minutes, compared to successive executions. If your use case is very time sensitive, container initialization time might become an operational issue.
- Don’t use global variables (those outside your function handler) to store any type of data that is specific to each function execution.
- Enable AWS X-Ray in order to identify potential bottlenecks in your Lambda execution. X-Ray can be useful when trying to visualize where the function’s execution time is being spent.
- Analyze the
init_durationmetric if Lambda Insights is enabled, and identify any potential issues with your functions’ initialization time. The Lambda Snapstart feature might be useful to reduce cold start delays, if your function is written in a supported runtime.
Treat event triggers, functions and final targets as a single environment (dev, test, prod, etc.)
In an event-driven architecture, Lambda functions are not isolated components. Lambda functions are often an intermediate step between an event and a final destination. Lambda functions can be automatically triggered by a number of AWS services (i.e. API Gateway, S3 events, CloudWatch Events, etc.). The Lambda function either returns, transforms or forwards data to a final target (i.e. S3, DynamoDB, SQS, Elasticache, OpenSearch, etc.). Some events contain only a reference to the request data, while other events contain the data itself.
Something like this:
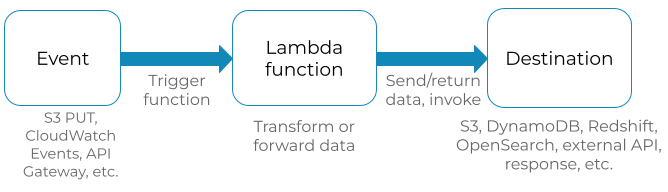
Ideally, there should be independent stages that contain their own set of AWS components for events, functions and data stores. For many system owners this is an obvious point. However, I’ve seen operational issues that stemmed from not following this principle.
This is probably due to how quick it becomes to build a service from the ground up using Lambda, that it’s also easy to forget about operational best practices.
There are frameworks you can use to alleviate this problem, such as Serverless, Chalice or Terraform, for example. You need to keep track of each component’s version and group them into a single environment version. This practice is really not too different from what you would need to do in any service oriented architecture before Lambda.
There is also the AWS Serverless Application Model, which allows you to define multiple components of your serverless application (API Gateway, S3 events, CloudWatch Events, Lambda functions, DynamoDB tables, etc.) as a CloudFormation stack, using a CloudFormation template. SAM has saved me a LOT of time when defining, developing and testing AWS components in my serverless applications. I really recommend using it as the standard way to launch serverless components, above the other available frameworks.
The AWS Lambda console offers a very helpful consolidated view of your Lambda functions, where you can see all components related to your Lambda functions, grouped as Applications. It’s definitely worth becoming familiar with it, but not as a way to launch and update Lambda configurations.
Don’t use the AWS Lambda console to develop Production code
The AWS Lambda console offers a web-based code editor that you can use to get your function up and running. This is great to get a feel of how Lambda works, but it’s neither scalable nor recommended.
Here are some disadvantages of using the Lambda console code editor:
- You don’t get code versioning automatically. If you make a bad mistake and hit the Save button, that’s it, your working code is gone.
- You don’t get integrations with GitHub or any other code repository.
- You can’t import modules beyond the AWS SDK. If you need a specific library, you will have to develop your function locally, create a .zip file and upload it to AWS Lambda - which is what you should be doing from the beginning anyways.
- If you’re not using versions and aliases, you’re basically tinkering with your live production code with no safeguard measures.
To emphasize, if you’re using the AWS console to set up your serverless components, you’re likely doing something wrong.
One thing about serverless applications is that the number of components can increase very quickly. For example, the number of functions and their respective triggers and data sources can quickly turn into an unmanageable situation. That’s why it’s very important to use tools such as the Serverless Application Model, where you define everything in a code-versioned template.
I only use the AWS Lambda console to view my Lambda functions, their configurations and look at some metrics, and pretty much nothing else.
Test your function locally
Since I don’t recommend using the Lambda console code editor, you’ll have to write your code locally, package it into a .zip file or container and deploy it to Lambda. Even though you can automate these steps, it’s still a tedious process that you’ll want to minimize.
That’s why it’s important to test your function before you upload it to AWS Lambda. Thankfully, there are tools that let you test your function locally, such as Python Lambda Local, or Lambda Local (for NodeJS). These tools let you create event and context objects locally, which you can use to create test automation scripts that will give you a good level of confidence before you upload your function code to the cloud.
And there’s also SAM Local, my preferred option, which is the official AWS CLI-based tool to test your functions locally, using Docker. SAM Accelerate is also a useful tool to speed up deployments to a development environment in AWS and test any development updates against other cloud resources (please note this is a recommended tool for development stages only).
You should consider these local development and test tools as your first gate, but not your only one. And this takes us to the next point…
Automate integration tests and deployments, just like any other piece of software
With AWS Lambda, you can implement a typical Continuous Integration flow and automate it using a service such as AWS Code Pipeline or other CI tools. A common flow would look like this:
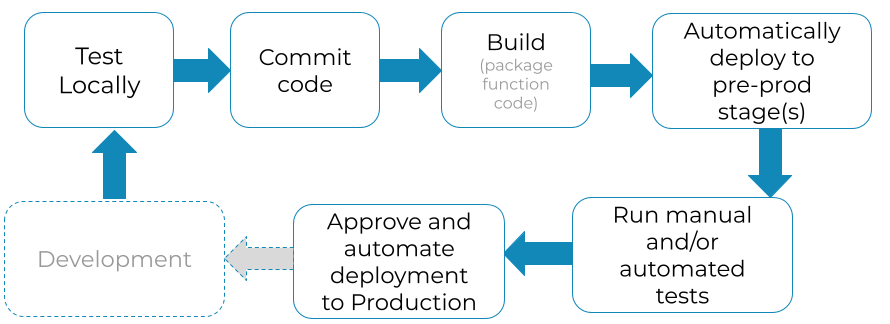
I really recommend using Serverless Application Model (SAM) + CodeBuild + CodePipeline, together. SAM makes the definition and creation of serverless resources easy, using CloudFormation syntax. CodeBuild simplifies and delivers a consistent way to create deployment packages. Using CodeBuild you’ll avoid some time-consuming errors that can pop up when you build your code in a local environment that is not running on EC2 and Amazon Linux. And finally, CodePipeline orchestrates the different steps required in your application deployment.
Using these 3 components together, I can literally go from local code to a full Lambda deployment with a single CLI command. No need to manually configure serverless components in the AWS console, create a .zip file, upload it and then run deployment commands and other things. I can just sit, relax and let CodePipeline do the work for me. CodePipeline has saved me and multiple teams countless hours of tedious, manual work.
One important consideration for critical environments (such as Production) is to use the AWS CodePipeline Manual Approval feature before deploying to Production. Ideally, your pipeline should create a CloudFormation Change Set that can be reviewed and approved manually before the final deployment to Production. I can say that reviewing Change Sets has helped me and my clients prevent bad deployments in the past.
Preferably, deploy your Lambda functions inside a VPC and use VPC Endpoints
An AWS Virtual Private Cloud (VPC) is a virtual network that you define and manage within AWS. It offers an additional layer of security by preventing the public exposure of cloud resources to entities outside of that VPC. Lambda functions support the option to be provisioned within a VPC. It’s worth noting that Lambda functions have to be deployed in Private Subnets and these subnets should use a NAT Gateway if they interact with external internet resources.
Also, if the function communicates with other backend resources, the best practice would be to restrict access to those resources to only within their own VPC, which would force Lambda functions to be deployed within that VPC.
For example, an RDS-managed database can be configured to only accept requests from within its own VPC, in which case any Lambda function that communicates with that RDS database has to be deployed within the same VPC. The same is true for functions that communicate with Elasticache clusters.
There are services, such as DynamoDB and S3, which support the concept of VPC Endpoints, which route requests to those resources within a particular VPC. This means that requests from a Lambda function deployed in a particular VPC can be made to fetch data from a DynamoDB table or S3 bucket without any data leaving the VPC, which enhances security and performance. There is a good number of AWS services that support VPC Endpoints, which should definitely be considered for any Lambda function deployed in a VPC and that interacts with those services.
Connecting to an RDS database? Use RDS Proxy
One of the key capacity indicators in an RDS database is the maximum number of database connections a particular instance can provide. This number varies by database engine and the size of the RDS instance (i.e. r5.large, r5.xlarge, etc.). Given that Lambda function invocations can grow to very large numbers, it’s not uncommon to experience situations where Lambda functions generate a number of database connections that exceeds the limit for a particular RDS instance type.
RDS Proxy is a managed database connection pool, which helps optimize the number of connections created by the backend database instance. Therefore, if your Lambda functions need to access an RDS database, it’s highly recommended to use RDS Proxy as a way to manage database connections and avoid situations where the database gets overloaded. In many cases, RDS Proxy also improves performance by simplifying the database connection process and reducing wait times for Lambda executions that interact with an RDS database.
From an application perspective, your Lambda functions need to connect to the RDS Proxy endpoint, instead of the actual RDS instance or cluster endpoint, and provide the credentials configured in the RDS Proxy. As the function invocations increase, RDS Proxy takes care of making database connections available to each Lambda execution, in a way that optimizes the connections created in the backend. Keep in mind that RDS Proxy is not available for all database engines supported in RDS, so just make sure your particular RDS configuration supports connecting via RDS Proxy.
Make sure your local development environment has exactly the same permissions that you have assigned to your Lambda function
One of the most critical configurations for your Lambda function is the IAM permissions that you assign to it. For example, if your function writes objects to S3, it must have an IAM Role assigned to it that grants Lambda permissions to call the PutObject S3 API. The same is true for any other AWS APIs that are invoked from your Lambda function. If the function tries to call an AWS API it doesn’t have permissions for, it will get an Access Denied exception. The best practice is to assign only the necessary IAM permissions to your functions and nothing else.
The problem is, many developers configure local environments using IAM credentials that have full access to AWS APIs. This might be OK in your dev environment using a dev AWS account, but it’s definitely not good for a Production environment. It’s common that a developer tests a function locally, in a dev environment with full privileges. Then uploads the function to Production, where the function has a limited permissions scope (as it should) and then see Access Denied exceptions.
I’ve seen this issue happen many times, therefore I’m including it in this article. To avoid this situation, make sure your local dev environment has exactly the same IAM permissions that you have granted your Lambda function in Production and that these permissions grant access to only the API operations and AWS resources that are relevant for that particular Lambda function.
Be aware of the retry behavior of your architecture in case of function failure
You can configure a number of AWS triggers to invoke your Lambda function. But what happens when your Lambda execution fails? (note I use the word “when” and not “if”). Before you decide if a particular function trigger is a good fit for your application, you must know how they handle Lambda function failures.
A Lambda function can be invoked in two ways, which result in a different error retry behavior:
- Synchronously. Retries are the responsibility of the trigger.
- Asynchronously. Retries are handled by the AWS Lambda service.
Here are some examples of AWS triggers and the way they invoke Lambda functions:
| AWS Trigger | Invocation |
|---|---|
| S3 Events | Event-driven, asynchronous. |
| Kinesis Streams | Lambda polling |
| SNS | Event-driven, asynchronous. |
| SES | Event-driven, asynchronous. |
| AWS Config | Event-driven, asynchronous. |
| Cognito | Event-driven, synchronous. |
| Alexa | Event-driven, synchronous. |
| Lex | Event-driven, synchronous. |
| CloudFront (Lambda @ Edge) | Event-driven, synchronous. |
| DynamoDB Streams | Lambda polling |
| API Gateway | Event-driven, synchronous. |
| CloudWatch Logs Subscriptions | Event-driven, synchronous. |
| CloudFormation | Event-driven, asynchronous. |
| CodeCommit | Event-driven, asynchronous. |
| CloudWatch Events | Event-driven, asynchronous. |
| AWS SDK | Both synchronous and asynchronous |
The retry behavior in case of failure varies by AWS service, therefore it’s important to check the AWS documentation and understand the error handling behavior for each AWS service integration with Lambda functions.
How a Lambda function is invoked is an important factor for choosing the right criteria for CloudWatch Alarms. For example, a single failure that blocks a whole Kinesis stream is likely a serious issue and you might want to lower your alarm threshold. But you might want to have a different alarm criteria for a single failure in a function triggered by SNS, when you know it will be retried up to 3 times.
You can read more about Lambda event sources here and about retry behaviour here.
In case of failure, Dead Letter Queues are a great tool
If your Lambda functions are invoked asynchronously, Dead Letter Queues are a great way to increase availability. DLQs allow you to send the payload of failed Lambda executions to a destination of your choice, which can be an SQS queue or an SNS topic. AWS Lambda retries failed asynchronous executions up to 2 times, after that it sends the payload to a DLQ. This is great for failure recovery, since you can reprocess failed events, analyze them and fix them. Here are some examples where DLQs could be very useful:
- Your downstream systems fail, which makes your Lambda execution to fail. In this case, you can always recover the payload from failed executions and re-execute them once your downstream systems recover.
- You encounter an application error or edge case. You can always analyze the records in your DLQ, correct the problem and re-execute as needed.
And there’s also the DLQ Errors CloudWatch metric, in case you can’t write payloads to the DLQ. This gives you even more protection and visibility to quickly recover from failure scenarios.
Don’t be too permissive with IAM Roles
As you might know, when you create a Lambda function you have to link an IAM Role to it. This IAM role gives the function permissions to execute AWS APIs on your behalf. In order to specify which permissions, you attach a policy to each role. Each policy includes which APIs can be executed and which AWS resources can be accessed by these APIs.
My main point is, avoid an IAM access policy that looks like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
A Lambda function with this policy can execute any type of operation on any type of AWS resource, including accessing keys in KMS, creating more admin IAM roles or IAM users, terminating all your EC2 instances or RDS nodes, accessing or deleting sensitive customer data stored in DynamoDB or S3, etc. Let’s say you have a Lambda function under development with a full access policy - if that’s the case, you’re basically opening a door to all your AWS resources in that account to any developer or contractor in your organization.
Even if you trust 100% the members of your team (which is OK) or you are the only developer in your AWS account, an over-permissive IAM Role opens the door to potentially devastating, honest human mistakes such as deleting or updating certain resources.
Here are some ways to minimize risks associated with granting IAM permissions to your Lambda functions:
- Not everyone in your company should have permissions for creating and assigning IAM Roles. You just have to be careful and avoid creating too much bureaucracy or slowing down your developers.
- Start with the minimum set of IAM permissions and add more as your function needs them.
- Audit IAM Roles regularly and make sure they don’t give more permissions than the Lambda function needs.
- Use CloudTrail to audit your Lambda functions and look for unauthorized calls to sensitive AWS resources.
- Use different accounts for development/test and production. There is some overhead that comes with this approach, but in general it is the best way to protect your production environments from unintended access or privilege escalation.
Restrict who can call your Lambda functions
Depending on how IAM Roles and IAM Users are created in your AWS account, it’s possible that a number of entities have elevated permissions - including the rights to invoke any Lambda function in your account. To further restrict who can invoke a particular function, you have the option to configure Lambda Resource Policies.
In addition to Resource Policies, you can configure CloudTrail to track not only the APIs called by your functions, but also which entities have invoked your Lambda functions.
Have a clean separation between different versions and environments
Versions and aliases
As your function evolves, AWS Lambda gives you the option to assign a version number to your function at that particular point in time. You can think of a version as a snapshot of your Lambda function. Versions are used together with aliases, which are a name you can use to point to a particular version number. Versions and aliases are very useful as ways to define the release your function code belongs to (i.e. 1.0, 1.1, 1.2, etc.)
By using versions and aliases, you can promote your code to Production in a safe way. This process can be automated, using the AWS API and using Continuous Integration tools. All of this can make your deployment process less painful as well as reduce human error in your operations.
Also, if you’re using CodeDeploy (which I really recommend), you can set up a deployment pipeline that gradually shifts traffic to a new version of your Lambda function. This way you can minimize customer impact in case there are issues with your latest deployment. You can also automate rollback to the previous working version based on CloudWatch alarms. More information on this feature can be found here.
Versions and aliases are a good way to promote code to a Lambda function, but you can also opt to deploy a set of functions using separate, independent, stage-specific CloudFormation stacks if you’re using the Serverless Application Model.
Use separate AWS accounts for Production and pre-Production
As mentioned earlier, using separate AWS accounts for development/test and production environments is a recommended best practice. Having different AWS accounts also reduces the possibility of human error on production environments and it helps with providing production access to the right IAM entities. You can also use automated CI/CD tools to deploy your code to different AWS accounts. For critical systems, this is my preferred option.
Use Environment Variables (and SSM Parameter Store / Secrets Manager) to separate code from configuration
If you’re building a serious software component, most likely you already avoid any type of hard-coded configuration in your source code. In the “server” world, an easy solution is to keep configurations somewhere in your file system or environment variables and access those values from your code. This gives a nice separation between application code and configuration and it allows you to deploy code packages across different stages (i.e. dev, test, prod) without changing application code - only configurations.
But how do you do this in the “serverless” world, where each function is stateless? Thankfully, AWS Lambda offers the Environment Variables feature for this purpose.
You can use SSM Parameter Store or Secrets Manager to store the actual values and use Environment Variables to store a reference to the object stored in Parameter Store or Secrets Manager. Just make sure that the actual sensitive values are not available directly as environment variables. Even better, if you’re handling secrets you can use the AWS Parameters and Secrets Lambda Extension, which improves how secrets are retrieved, improving security, performance and cost.
Depending on the invocation volume of your Lambda function and the nature of the secrets and your use case, it might be an option to cache these values in your Lambda function and reduce the number of API calls made to Parameter Store or Secrets Manager, improving performance and optimizing cost. This is something that needs to be evaluated on a case-by-case basis as there might be situations where it’s not an acceptable solution.
You can also restrict which IAM Users/Roles have access to a particular entry in SSM Parameter Store or Secrets Manager.
Make sure you can quickly roll back any code changes
Deploying code to production is NEVER risk free. There’s always the possibility of something going wrong and your customers suffering as a result. While you can’t eliminate the possibility of something bad happening, you can always make it easier to roll back any broken code.
Versions and aliases are extremely handy in case of an emergency rollback. All you have to do is point your PROD alias to the previous working version. CodePipeline also offers simple ways to redeploy code from a previous successful pipeline execution.
Test for performance
AWS promises high scalability for your Lambda functions, but there are still resource limits you should be aware of. One of them is that by default you can’t have more than 1,000 concurrent function executions - if you need a higher value you can submit a Service Limit Increase to AWS Support, though. Each execution has limits too. There is a limit to how much data you can store in the temporary file system (10GB), the number of threads or open files (1,024). The maximum allowed execution time is 900 seconds (15 minutes) and there are limits to the request and response payload size (6MB for synchronous invocations, 256KB for asynchronous).
Therefore, I strongly recommend you identify both steady and peak load scenarios and execute performance tests on your functions. This will give you confidence that your expected usage in Production doesn’t exceed any of the Lambda resource limits.
Regarding performance, for compute-intensive applications, it’s recommended to evaluate if the function code is compatible with arm64 architecture (AWS Graviton2 processor) and if so, test the functions using this architecture. This could bring significant performance improvements.
When executing performance tests, you should quantify the execution time and frequency, so you can estimate the monthly cost of your function, given your expected usage in Production. Also, this is a good time to use Application Performance Monitoring (APM) and tracing tools like AWS X-Ray, NewRelic or DataDog in order to identify performance bottlenecks and fine-tune your application.
Estimate Cost at Scale
AWS Lambda offers 1 million monthly free executions, and each additional million costs only $0.20. When it comes to price, Lambda is always the cheapest option, right? Well, not really. There are situations where Lambda pricing can be substantially higher compared to running your workload using EC2. If you have a process that runs infrequently, then Lambda will likely be cheaper compared to EC2. But if you have a resource-intensive process that runs constantly, at high volume, that’s when going serverless might cost you more compared to EC2.
Let’s say you have a function that runs at a volume of 100 transactions per second (approximately 259 million executions per month). Each execution consumes 1,000ms and requires 512MB of memory. You would pay approximately $2,300/month for this function. Let’s say that you can handle the same workload with a cluster of 10 m5d.large instances (SSD local storage), in which case you would pay $813/month.
The difference? This Lambda function would cost you $17,844 more per year compared to EC2.
Also, consider using AWS Compute Savings Plans to reduce cost. Here is an article I wrote, which explains Savings Plans in detail. The chart below shows the yearly cost of a function, based on different combinations of execution time and assigned memory (not counting the free tier) and compares different Savings Plans scenarios vs. On Demand.
* Savings Plans don’t offer a discount on the cost related to the number of Lambda executions, they only cover Compute costs. The results in the chart above include pricing for all dimensions, including number of requests and compute.
Don’t forget about CloudWatch Logs Cost
Lambda functions write their output to CloudWatch Logs, which has a cost of $0.50/GB for ingested data and $0.03/GB for data storage. Let’s take a look at the following table, which shows different monthly cost for CloudWatch Logs ingestion based on Lambda Transactions Per Second and log message payload (KB) sent to CloudWatch Logs per Lambda execution:
| TPS | 1KB | 128KB | 256KB |
|---|---|---|---|
| 1 | $13 | $166 | $332 |
| 10 | $130 | $1,659 | $3,318 |
| 100 | $1,296 | $16,589 | $33,178 |
As you can see, CloudWatch Logs ingestion can actually cost more than Lambda executions. I’ve seen many cases in Production where this is the case, so it’s definitely something to be aware of before typing that console.log(...) statement in your Lambda function code.
Conclusions
- Lambda is a great AWS product. Removing the need to manage servers delivers great value, but running a reliable Lambda-based application in Production requires operational discipline - just like any other piece of software your business depends on.
- Lambda (aka FaaS or Serverless) is a relatively new paradigm and it comes with its own set of challenges, such as configurations, understanding pricing, handling failure, assigning permissions, configuring metrics, monitoring and deployment automation.
- It is important to perform load tests, understand Lambda pricing at scale and make an informed decision on whether a FaaS architecture brings the right balance of performance, price and availability to your application.
Are you considering using a serverless architecture, or already have one running?
I have many years of experience working with Lambda functions and other serverless components, including high volume applications. I can certainly help you with designing, implementing and optimizing your serverless components. Just click on the Schedule Consultation button below and I’ll be happy to have a chat with you.
