* I recently published this article with an updated set of tests leveraging the TPC-DS benchmark.
I wrote this article comparing three tools that you can use on AWS to analyze large amounts of data: Starburst Presto, Redshift and Redshift Spectrum. As an end user, it’s important for me to dive into areas that are essential when using a data analysis tool, such as infrastructure setup, data setup, performance, maintenance and cost.
In other words, “What do I need to do in order to run this workload, how fast will it be and how much will I pay for it?”
But as you probably know, there are more data analysis tools that one can use in AWS. One in particular I’m going to take a look at is Elastic Map Reduce (EMR). I thought more analysis was warranted - this time comparing Starburst Presto against solutions in EMR that support a SQL interface: EMR Presto, EMR Spark and EMR Hive.
Let’s start by describing these solutions…
- Presto is an open source distributed ANSI SQL query engine. It supports the separation of compute and storage. Meaning, it can query data that is stored externally - for example, Amazon S3. Starburst Presto is an enterprise-ready distribution of Presto made available by Starburst Data, a company founded by many of the leading committers to the Presto project.
- AWS Elastic Map Reduce (EMR) is a managed service offered by AWS. It supports a number of data analysis frameworks, such as Hadoop, Presto, Hive, Spark, and others. Through EMR you can launch a cluster of EC2 instances with pre-installed software in them and some default configurations. You specify the frameworks you want to include in your cluster as well as EC2 instance types, cluster size and your own framework-specific configurations (if you don’t want to use EMR default ones).
- EMR Presto. This is the Presto distribution supported by AWS EMR. At the time of writing, the latest EMR release is emr-5.16.0, which comes with Presto 0.203.
- Spark is an open source, distributed, in-memory, data analysis framework that is also supported by EMR. For this article, I executed TPC-H SQL queries using the Spark CLI.
- Hive is is an open source data warehouse solution built on top of Apache Hadoop. HiveQL also allows users to use SQL syntax to analyze data. EMR Hive uses Tez as the default execution engine, instead of MapReduce.
Infrastructure Setup
I’ll start with the steps I followed, across all solutions, in order to run these tests:
- I used the same 1TB, TPC-H, ORC-formatted (Optimized Row Columnar) dataset from my previous article. TPC-H is considered an industry standard for measuring database performance and it consists of a standard data set and queries that I executed for these tests. All tests read data from the same 1TB TPC-H data set, stored in AWS S3. This data set contains approximately 8.66 billion records.
- I set up an RDS-backed Hive Metastore using the steps described in the AWS documentation. All tests pointed to the same Hive Metastore, which points to the S3 location for the ORC files. Column Statistics are used by Presto, Spark and Hive for query plan optimization.
- I used EMR release emr-5.16.0 for all EMR tests.
- I executed tests with clusters consisting of 10 r4.4xlarge workers and 1 master node running also on a r4.4xlarge EC2 instance. This cluster size turned out to be problematic for EMR Presto and for EMR Hive (more details below). Regardless of cluster size, there are 3 queries in the TPC-H query set that could not be executed using EMR Spark, due to incompatible SQL syntax (also, more details below).
EMR Presto
My first attempt at running a test was using emr-5.16.0, which comes with Presto 0.203.
The default EMR configuration caused my initial tests to fail, since EMR automatically assigned
30GB for query.max-memory, which is too low for the 1TB data set. Therefore I configured
query.max-memory=550GB and query.max-memory-per-node=55GB (the maximum I could use for
10 r4.4xlarge nodes). I tried a few configurations, including session setting resource_overcommit=true,
which still resulted in 3 queries (q09, q11 and q21) consistently failing due to memory errors.
The only way to make those 3 queries execute would be to increase cluster size to 15 worker
nodes and set query.max-memory=850GB.
EMR Hive
I also launched a 10-worker cluster running emr-05.16, which comes with Hive v2.3.3. I used EMR default configurations in my first attempt, which failed after only 6 queries due to memory errors the cluster could not recover from. I tried a few combinations of parameters, including yarn.nodemanager.resource.memory-mb, tez.am.resource.memory.mb, tez.am.grouping.max-size and others. None of my attempts were successful when I tried custom configurations and a 10-worker cluster.
After I failed to optimize Hive using emr-05.16.0, I tried a few runs using emr-05.15.0. EMR default values allowed me to execute up to 9 queries successfully, but any more than that and everything started to fail and the cluster became unusable. Again, I tried a few combinations with different memory settings, but none of them worked.
In addition to cluster failures when using a 10-worker cluster, queries q11, q15, q21 and q22 failed due to incompatible SQL syntax. For example, I experienced the following errors: “Only SubQuery expressions that are top level conjuncts are allowed”, “Only 1 SubQuery expression is supported.” While it might be possible to rewrite those queries for Hive compatibility, doing so would result in altering the query structure significantly. From a user perspective, this is not optimal.
After my previous 2 attempts failed, I decided to try again using emr-05.16.0 with EMR default configurations and increase cluster size gradually. It was only when my cluster had 15 worker nodes that queries could execute successfully (except the ones with SQL syntax incompatibility).
Hive is the framework that I found the most difficult to work with for this particular data set and queries.
EMR Spark
I launched my EMR Spark cluster using emr-05.16, which comes with Spark 2.3.1. In my first attempt, some queries failed due to insufficient memory, therefore I added maximizeResourceAllocation=true as a custom configuration value. Then I was able to successfully run the test using a 10-worker node cluster, with the exception of queries q07, q08 and q09, which failed due to incompatible SQL syntax. Spark was not able to process subqueries with the following format: SELECT … FROM ( SELECT … FROM …) AS temp_table GROUP BY …
Starburst Presto
Starburst Presto offers an AMI in the AWS Marketplace. There is a CloudFormation template that can be downloaded from the AWS Marketplace page too, which is what I used to launch my cluster. Using CloudFormation parameters, I can select the cluster size and EC2 instance type (r4.4xlarge). At the time of writing, the supported version of Presto is v0.203. Using CloudFormation, the cluster was up and running in less than five minutes.
It’s worth noting that Starburst Presto was the only solution that allowed me to execute all 22 TPC-H queries using a 10-worker cluster, without me spending any time changing default configurations. This is an important distinction for me, because it’s always more desirable to launch a cluster and immediately be able to analyze data instead of spending time trying to tune custom configurations or re-write queries.
Benchmark Execution
For each solution, I ran the same set of 22 queries that are part of the TPC-H benchmark. These queries were executed sequentially against the same 1TB, ORC-formatted dataset stored in S3. Each query set was executed 3 times and the average of these 3 executions is the number I report in my results.
Performance Comparison
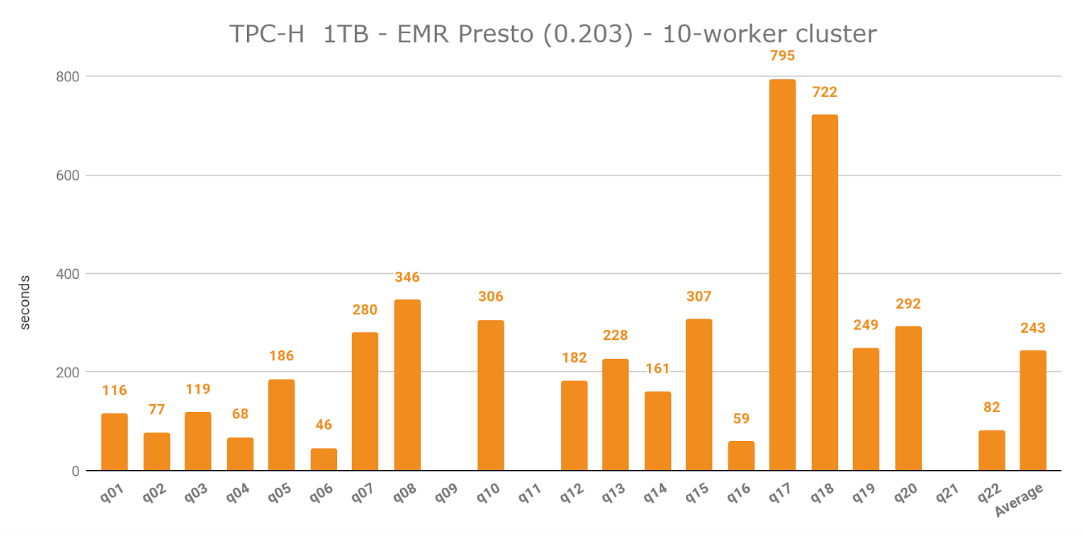
With 10 worker nodes, I was able to execute 19 out of 22 TPC-H queries using EMR Presto which resulted in an average of 243 seconds per query execution - q09, q11 and q21 failed due to insufficient memory errors. The fastest query was q06, which took 46 seconds to execute.
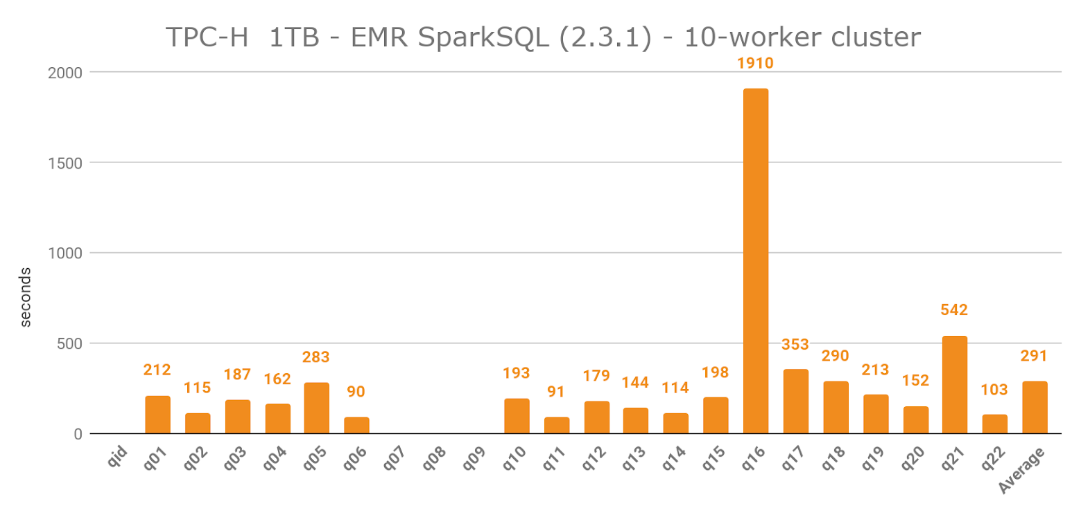
I ran into some problems related to Spark not accepting the syntax in queries q07, q08 and q09. Excluding these 3 queries, execution average was 291 seconds per query. The fastest query was q06, which took 90 seconds to execute.
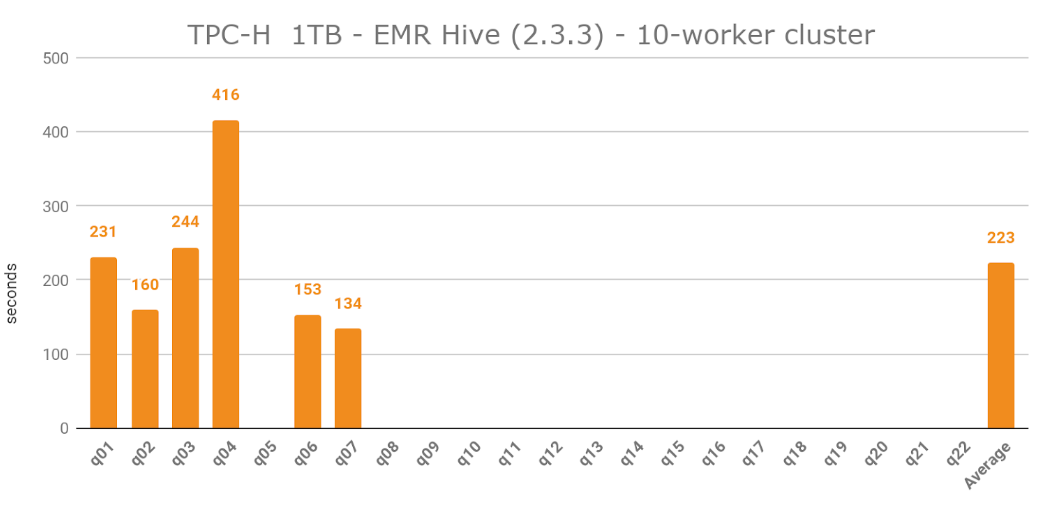
EMR Hive also presented a number of challenges in terms of SQL syntax for TPC-H queries, particularly related to subquery expressions. Hive couldn’t execute the following queries due to incompatible SQL syntax: q11, q13, q15, q21 and q22.
Besides those 4 queries, the rest failed when the cluster ran into memory errors it couldn’t recover from. It was only when I launched a 15-worker cluster that I could complete an execution (excluding those queries with SQL syntax incompatibility).
Below are the results when using a 15-worker cluster:
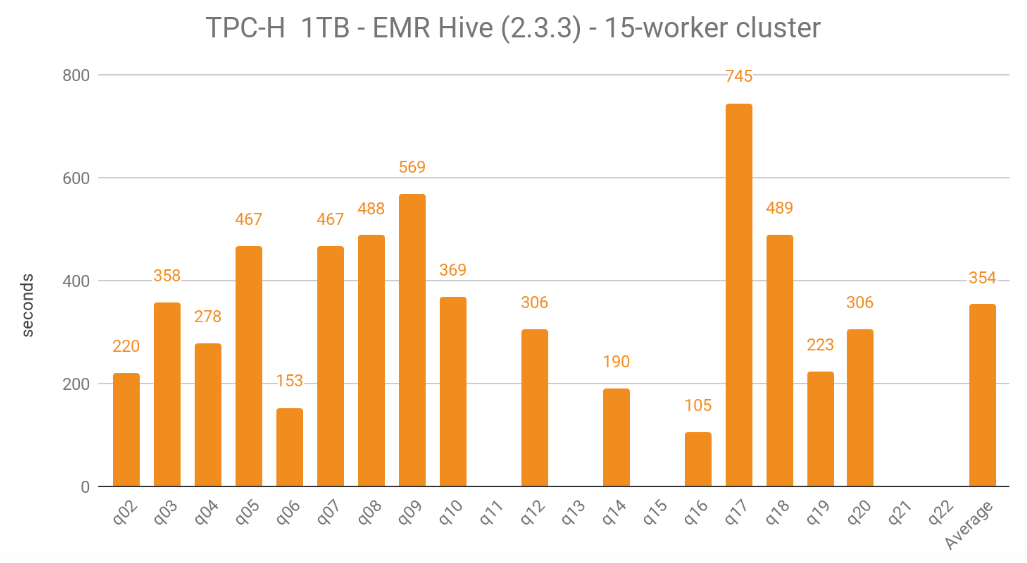
The average execution time for a 10-worker cluster was 223 seconds, but I’m not counting this Hive execution as successful, due to the high percentage of failed queries. Using a 15-worker cluster, which resulted in 17 successful queries, the average execution was 354 seconds, which was significantly higher compared to other engines running on a 10-worker cluster. The fastest query was q16, which took 105 seconds to execute. With regard to performance, EMR Hive was the platform I was least satisfied with.
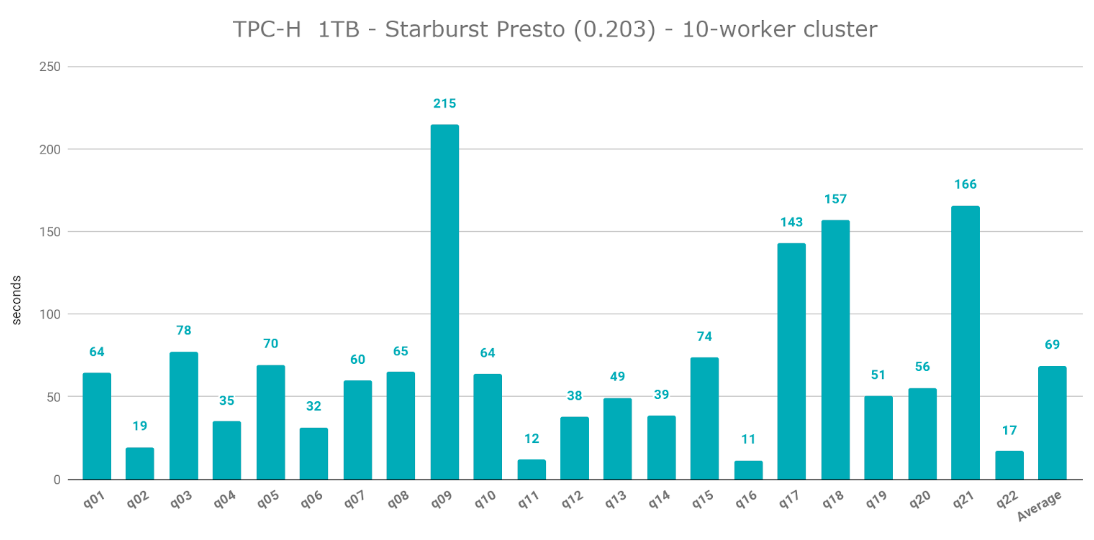
The average query execution for Starburst Presto was 69 seconds - the fastest among all 4 engines under analysis. The fastest query was q16, which took 11 seconds to execute. Unlike EMR Presto, I could execute all 22 queries without experiencing insufficient memory errors. This is likely due to Starburst Presto’s Cost-Based Optimizer.
The graph below shows a comparison of EMR Presto, EMR Spark and Starburst Presto, using a 10-worker cluster:
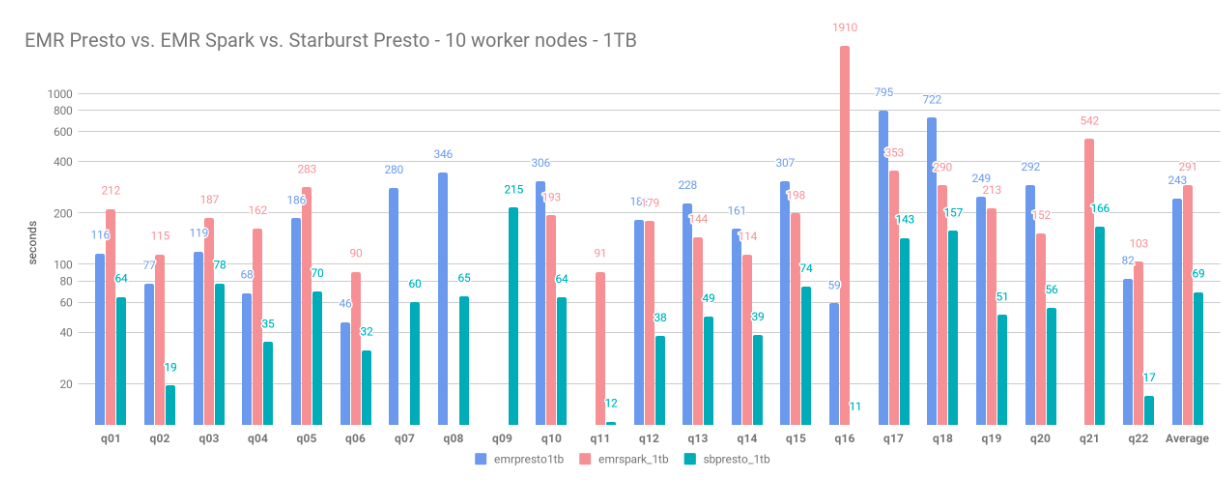
… and the results, in seconds, per query and engine:
| qid | EMR Presto 0.203 | EMR Spark 2.3.1 | SB Presto 0.203 |
|---|---|---|---|
| q01 | 116 | 212 | 64 |
| q02 | 77 | 115 | 19 |
| q03 | 119 | 187 | 78 |
| q04 | 68 | 162 | 35 |
| q05 | 186 | 283 | 70 |
| q06 | 46 | 90 | 32 |
| q07 | 280 | N/A | 60 |
| q08 | 346 | N/A | 65 |
| q09 | N/A | N/A | 215 |
| q10 | 306 | 193 | 64 |
| q11 | N/A | 91 | 12 |
| q12 | 182 | 179 | 38 |
| q13 | 228 | 144 | 49 |
| q14 | 161 | 114 | 39 |
| q15 | 307 | 198 | 74 |
| q16 | 59 | 1910 | 11 |
| q17 | 795 | 353 | 143 |
| q18 | 722 | 290 | 157 |
| q19 | 249 | 213 | 51 |
| q20 | 292 | 152 | 56 |
| q21 | N/A | 542 | 166 |
| q22 | 82 | 103 | 17 |
| Average | 243 | 291 | 69 |
Based on these numbers, Starburst Presto is the engine that delivers the best performance. Using 10 worker nodes, Starburst Presto’s query execution average was 69 seconds: 4.2x faster than EMR Spark and 3.5x faster than EMR Presto. In terms of individual query executions, Starburst Presto fastest query execution was 11 seconds: 4.2x faster than EMR Presto and 7.8x faster than EMR Spark.
The table below shows the average query execution time relative to each engine, as a percentage.
| relative to: | |||
|---|---|---|---|
| EMR Presto 0.203 | EMR Spark 2.3.1 | SB Presto 0.203 | |
| EMR Presto 0.203 | N/A | 84% | 353% |
| EMR Spark 2.3.1 | 120% | N/A | 423% |
| SB Presto 0.203 | 28% | 24% | N/A |
Cost Comparison
The following calculations include cost per hour for each solution, as well as a monthly projection assuming 720 hours per month. Both EMR and Starburst Presto share a pricing model where you pay the regular EC2 instance compute fee plus a license fee. Also, EC2 and EMR support per-second billing.
I made sure my S3 bucket and EC2 instances were located in the same AWS region (us-east-1), therefore I didn’t incur in any data transfer fees. Otherwise, you should expect inter-regional data transfer fees between S3 and EC2. These charges can range between $10 and even $160 per TB, depending on the origin and destination regions. Most regions in the US result in $20 per TB of inter-regional data transfer.
EMR: Presto, Spark and Hive
EMR offers the same price structure for these 3 engines. You pay for EC2 compute, plus an EMR fee per EC2 instance. This EMR fee varies by instance type, so I’m including the one for an r4.4xlarge ($0.266 per hour).
Below is the cost break-down for a 10-worker cluster running on r4.4xlarge instances, plus a master node:
| Component | Price Dimension | Usage | Hourly Cost | Monthly Cost |
|---|---|---|---|---|
| Data store | S3 Storage | 1TB | $0.03 | $23 |
| EMR Cluster | EC2 compute | 11 r4.4xlarge instances | $11.70 | $8,426.88 |
| EMR Cluster | EMR fee | 11 units ($0.266 per hour, per server) | $2.93 | $2,106.72 |
| Hive Metastore | EMR Hive Cluster | 1 m4.large (EC2 + EMR cost) | $0.13 | $93.60 |
| Hive Metastore | RDS Data store | 1 RDS MySQL t2.micro, 20GB SSD storage | $0.02 | $14.40 |
| Total: | $14.81 | $10,665 |
Note: The cost for a 15-worker EMR cluster would be $21.46 per hour, or a monthly projection of $15,453. This is the cost you would expect for EMR Hive, given that it could only handle this dataset with 15 worker nodes.
Starburst Presto
The following calculation includes EC2 cost plus a Starburst license, as described in the AWS Marketplace page.
| Component | Price Dimension | Usage | Hourly Cost | Monthly Cost |
|---|---|---|---|---|
| Data store | S3 Storage | 1TB | $0.03 | $23.00 |
| Starburst Presto cluster | EC2 compute | 11 r4.4xlarge instances | $11.70 | $8,426.88 |
| Starburst Presto cluster | License | 11 licenses ($0.27 per hour, per server) | $2.97 | $2,138.40 |
| Hive Metastore | EMR Hive Cluster | 1 m4.large (EC2 + EMR cost) | $0.13 | $93.60 |
| Hive Metastore | RDS Data store | 1 RDS MySQL t2.micro, 20GB SSD storage | $0.02 | $14.40 |
| $14.86 | $10,696 |
It’s worth noting that the average TPC-H query took Starburst Presto a fraction of the time it took other engines running on EMR (between 24% and 28% on average). Results will vary according to your specific workloads and engine, but having a faster tool will result in less compute time consumed.
With this in mind and if you terminate or reduce cluster size during idle periods, I think it’s fair to expect about 4x less compute cost when using Starburst Presto.
Cost Management Recommendations As you can see, leaving any of these clusters running 24/7 can quickly cause your AWS bill to grow, so it’s important to keep a close eye on cost, particularly compute hours. Here are some recommendations:
- Make it easy to launch a cluster by using automation tools, such as custom scripts or CloudFormation templates. This way you or your team can terminate a cluster without worrying too much about how long it’ll take to launch a new one. Starburst Presto already has a CloudFormation template available, which I recommend as the standard way to launch AWS components.
- Both EMR and Starburst Presto support Auto Scaling. I recommend applying rules that decrease cluster size to a minimum during idle periods, based on CPU Utilization metrics. You can also configure Scheduled Actions to decrease cluster size outside of business hours. This will not only decrease cost and save you time, but it will also minimize the possibility of getting a nasty AWS billing surprise due to human error.
- All the solutions described in this article support EC2 Reserved instances. My advice is to test and monitor your clusters - and once you find an optimal EC2 instance type for your workload, commit to buying Reserved instances. Just make sure the number of Reserved instances corresponds to the number of EC2 instance hours that you expect your cluster will need per month. You can end up saving at least 40% by doing this.
- You can also use Spot Instances. It is possible that instances will get terminated in the middle of an execution, but if you’re OK with this possibility you could save as much as 80% compared to On-Demand EC2 cost.
- Make sure your S3 bucket and EC2 instances live in the same AWS region. Otherwise you would incur in S3 inter-regional data transfer fees, which range between $10 and $160 per TB, depending on the origin and destination AWS regions. Not to mention performance, which will also be better if all resources are launched in the same region.
Conclusions
- Starburst Presto is the only solution that could handle all 22 TPC-H queries using a 10-worker cluster. Even though EMR Spark did not experience memory errors (unlike EMR Presto and EMR Hive), there were 3 queries that could not be executed due to incompatible SQL syntax.
- Using 10 worker nodes, Starburst Presto’s query execution average was 69 seconds: 4.2x faster than EMR Spark and 3.5x faster than EMR Presto.
- Due to EC2 compute cost, being able to analyze the same amount of data in less time results in approximately 75% lower cost for this particular data set when using Starburst Presto.
- Of all the solutions, Starburst Presto was the only one where I could execute all queries without providing any custom configurations. As an end user, just being able to launch a cluster and complete my tests saved me a considerable amount of time.
- Setting aside the issues I encountered with EMR default configurations for the TPC-H data set, launching a cluster using EMR or Starburst Presto was equally simple. I was able to have a cluster up and running in less than 5 minutes. I could also modify cluster size in less than 2 minutes, either by adding or removing nodes.
- If you’re careful about terminating or reducing cluster size during idle periods, executing queries quickly will result in less compute cost for you. Based on performance results, for this particular data set and queries, Starburst Presto’s faster query execution times translated into compute cost savings of about 75%.
EMR is a solid tool for performing data analysis in the cloud and I’m sure it will continue to be so. Having these tests and considering infrastructure setup, cost and performance, I think Starburst Presto delivered a preferable solution compared to EMR Presto, EMR Spark and EMR Hive, for this particular data set.
