
Choosing the right Data Analytics solutions in the cloud is an increasingly important area for many applications. While AWS offers a wide range of managed services, it’s also important to explore other solutions that can be deployed in AWS and that can bring benefits to application owners who are looking to analyze large amounts of data. One tool with these characteristics is Starburst Enterprise.
In this article, I’ll compare performance, infrastructure setup, maintenance and cost related to 4 Data Analytics solutions: Starburst Enterprise, EMR Presto, EMR Spark and EMR Hive. As in previous articles, I want to answer the following: “What do I need to do in order to run this workload, how fast will it be and how much will I pay for it?”
Let’s do a refresh of the solutions under test…
- AWS Elastic Map Reduce (EMR) is a managed service offered by AWS. It supports many data analysis platforms, such as Hadoop, Presto, Hive, Spark, and others. With EMR, developers can launch a compute cluster with pre-installed data analytics software and use default or custom configurations. EMR supports launching compute clusters consisting of EC2 instances or Fargate containers and it allows to configure compute capacity as well as Auto Scaling configurations to adjust compute resources based on system load.
- Starburst Enterprise is a commercial distribution of Trino (formerly known as PrestoSQL) It can query data stored in multiple data sources (e.g. AWS S3, Hadoop, SQL and NoSQL databases, Google Cloud Storage, etc.). It can be easily launched in AWS through the AWS Marketplace.
- EMR Presto is the Presto distribution delivered by AWS EMR.
- Spark is an open source, distributed, in-memory, data analysis framework designed for large scale, that is also available in EMR.
- Hive is an open source data warehouse solution built on top of Apache Hadoop. HiveQL also allows users to use SQL syntax to analyze data and it’s available in EMR as a managed solution. Of all platforms in this analysis, Hive is the one with the longest time in the market, with its initial release back in 2010.
Data and Infrastructure Setup
Below are the steps I followed, across all solutions, in order to run these tests:
Data
In all tests I leveraged the TPC-DS benchmark, which consists of a data set and queries created by the Transaction Processing Performance Council (TPC). TPC-DS is an industry standard when it comes to measuring performance across data analytics tools and databases in general. Please note, however, that this is not an official audited benchmark as defined by the TPC rules.
I created two 1TB TPC-DS data sets (ORC and Parquet), stored in AWS S3. Data sets contain approximately 6.35 billion records stored in 24 tables. The TPC-DS standard also consists of 99 SQL queries. For this test, the following tables were partitioned as described below:
- catalog_returns on cr_returned_date_sk
- catalog_sales on cs_sold_date_sk
- store_returns on sr_returned_date_sk
- store_sales on ss_sold_date_sk
- web_returns on wr_returned_date_sk
- web_sales on ws_sold_date_sk
Infrastructure
- In order to maintain a data catalog, I set up an RDS-backed Hive Metastore using the steps described in the AWS documentation. This was powered by a single m4.large EC2 instance managed by EMR and a t3.medium RDS DB instance. All tests used the same Hive Metastore, which points to the S3 location for ORC and Parquet files, respectively.
- I used Starburst Enterprise version 350-e available in the AWS Marketplace and applied default configurations. I launched the cluster using the CloudFormation template available in the AWS Marketplace page. The CloudFormation template allows users to configure compute and storage capacity (EC2 instance types and count, EBS volume types and size ) as well as custom Presto configurations (i.e. memory allocation, metastore location, etc.). The stack creates an Auto Scaling Group with all the provisioned EC2 instances and a number of custom CloudWatch metrics useful for detailed monitoring and troubleshooting. Support for CloudFormation allows application owners to easily implement automation procedures that launch, update or terminate clusters as needed.
- I used the following versions for EMR tests: Presto 0.230, Spark 3.0.0 and Hive 3.1.2. I applied default EMR configurations in all tests (i.e. memory allocation per node or maximum allocation per query). Launching an EMR cluster can also be automated by using the AWS SDK or CLI, which simplifies infrastructure operations in general.
- For EMR Hive, I enabled Live Long and Process (LLAP), which is a feature that is expected to increase performance by introducing in-memory caching. I configured default LLAP settings, which according to AWS documentation result in EMR allocating about 60 percent of cluster YARN resources to Hive LLAP daemons.
- I executed all tests with clusters consisting of 20 r5.4xlarge workers and 1 master node running also on a r5.4xlarge EC2 instance.
Benchmark Executions
For each platform, I ran the same set of 99 queries that are part of the TPC-DS benchmark. Queries were executed sequentially against the same 1TB dataset stored in S3. For each platform, each query set was executed 4 times in a sequential order and the average of these 4 executions is the number I report in this article. Each test for a particular platform was executed on a fresh cluster, in order to make all conditions equal. I ran ANALYZE statements for each of the 24 tables that are part of the test.
I ran separate tests for both ORC and Parquet data formats and below are the results.
ORC - Performance Comparison
| qid | Starburst 350-e | EMR Presto 0.230 | EMR Spark 3.0.0 | EMR Hive 3.1.2 LLAP |
|---|---|---|---|---|
| q01 | 7 | 11 | 39 | N/A |
| q02 | 22 | 23 | 43 | N/A |
| q03 | 4 | 23 | 28 | 34 |
| q04 | 33 | N/A | 127 | 163 |
| q05 | 16 | 70 | 52 | 139 |
| q06 | 4 | 44 | 33 | 35 |
| q07 | 7 | 19 | 36 | 53 |
| q08 | 7 | 11 | 32 | 26 |
| q09 | 24 | 22 | 71 | 144 |
| q10 | 6 | 24 | 38 | 40 |
| q11 | 19 | N/A | 62 | 115 |
| q12 | 2 | 10 | 30 | 28 |
| q13 | 8 | 64 | 42 | 60 |
| q14 | 70 | 185 | 76 | N/A |
| q15 | 4 | 11 | 33 | 37 |
| q16 | 15 | 52 | 67 | N/A |
| q17 | 9 | 40 | 40 | 61 |
| q18 | 6 | 13 | 39 | 62 |
| q19 | 6 | 21 | 32 | 33 |
| q20 | 3 | 11 | 30 | 29 |
| q21 | 6 | 14 | N/A | N/A |
| q22 | 13 | 10 | 33 | 138 |
| q23 | 71 | 116 | 117 | N/A |
| q24 | 37 | 47 | 76 | N/A |
| q25 | 7 | 28 | 40 | 60 |
| q26 | 4 | 11 | 32 | 54 |
| q27 | 6 | 19 | 34 | N/A |
| q28 | 19 | 21 | 70 | 146 |
| q29 | 10 | 27 | 49 | 120 |
| q30 | 5 | 17 | 38 | N/A |
| q31 | 9 | 29 | 41 | 58 |
| q32 | 3 | 11 | 31 | N/A |
| q33 | 6 | 17 | 35 | 30 |
| q34 | 4 | 12 | N/A | 44 |
| q35 | 7 | 11 | 43 | 82 |
| q36 | 4 | 22 | 34 | N/A |
| q37 | 11 | 10 | 36 | 116 |
| q38 | 10 | 16 | 50 | 108 |
| q39 | 3 | 28 | 36 | 36 |
| q40 | 13 | 61 | 41 | 159 |
| q41 | 1 | 1 | 24 | 18 |
| q42 | 3 | 15 | 28 | 28 |
| q43 | 7 | 24 | 30 | 51 |
| q44 | 11 | 11 | 48 | 147 |
| q45 | 3 | 11 | 33 | 42 |
| q46 | 6 | 25 | 34 | 57 |
| q47 | 36 | 124 | 43 | 76 |
| q48 | 7 | 31 | 38 | 55 |
| q49 | 14 | 81 | 48 | 157 |
| q50 | 11 | 43 | 62 | 177 |
| q51 | 12 | 22 | 48 | 105 |
| q52 | 5 | 15 | 28 | 27 |
| q53 | 5 | 13 | N/A | 57 |
| q54 | 12 | 31 | 36 | 135 |
| q55 | 3 | 15 | 28 | 27 |
| q56 | 5 | 18 | 34 | 29 |
| q57 | 20 | 64 | 41 | 76 |
| q58 | 7 | 45 | N/A | 48 |
| q59 | 24 | 31 | 40 | 143 |
| q60 | 7 | 19 | 35 | 31 |
| q61 | 6 | 41 | 30 | 27 |
| q62 | 11 | 28 | N/A | N/A |
| q63 | 5 | 14 | 35 | 53 |
| q64 | 72 | 122 | 75 | 167 |
| q65 | 17 | 30 | 51 | 132 |
| q66 | 6 | 78 | 39 | 69 |
| q67 | 59 | 501 | 402 | 244 |
| q68 | 7 | 34 | 33 | 31 |
| q69 | 5 | 10 | 36 | 32 |
| q70 | 17 | 33 | 41 | N/A |
| q71 | 6 | 20 | 36 | 33 |
| q72 | 34 | N/A | 53 | 1501 |
| q73 | 4 | 16 | 29 | 27 |
| q74 | 15 | 69 | 52 | 98 |
| q75 | 30 | 82 | N/A | 163 |
| q76 | 12 | 31 | 50 | 153 |
| q77 | 11 | 74 | 40 | 37 |
| q78 | 52 | 104 | 74 | 501 |
| q79 | 5 | 30 | 33 | 35 |
| q80 | 23 | 84 | 54 | 166 |
| q81 | 6 | 15 | 40 | N/A |
| q82 | 11 | 25 | 41 | 121 |
| q83 | 6 | 26 | N/A | 34 |
| q84 | 11 | 15 | 35 | 138 |
| q85 | 15 | 23 | 57 | 166 |
| q86 | 4 | 10 | 31 | N/A |
| q87 | 10 | 24 | 54 | 123 |
| q88 | 23 | 70 | 48 | 118 |
| q89 | 6 | 16 | 35 | 56 |
| q90 | 11 | 10 | 33 | 120 |
| q91 | 4 | 45 | 30 | 20 |
| q92 | 3 | 10 | 31 | N/A |
| q93 | 27 | 99 | 74 | 155 |
| q94 | 13 | 36 | 60 | N/A |
| q95 | 34 | 83 | 83 | N/A |
| q96 | 10 | 10 | 29 | 116 |
| q97 | 12 | 31 | 46 | 119 |
| q98 | 3 | 19 | 31 | 31 |
| q99 | 10 | 61 | 42 | 142 |
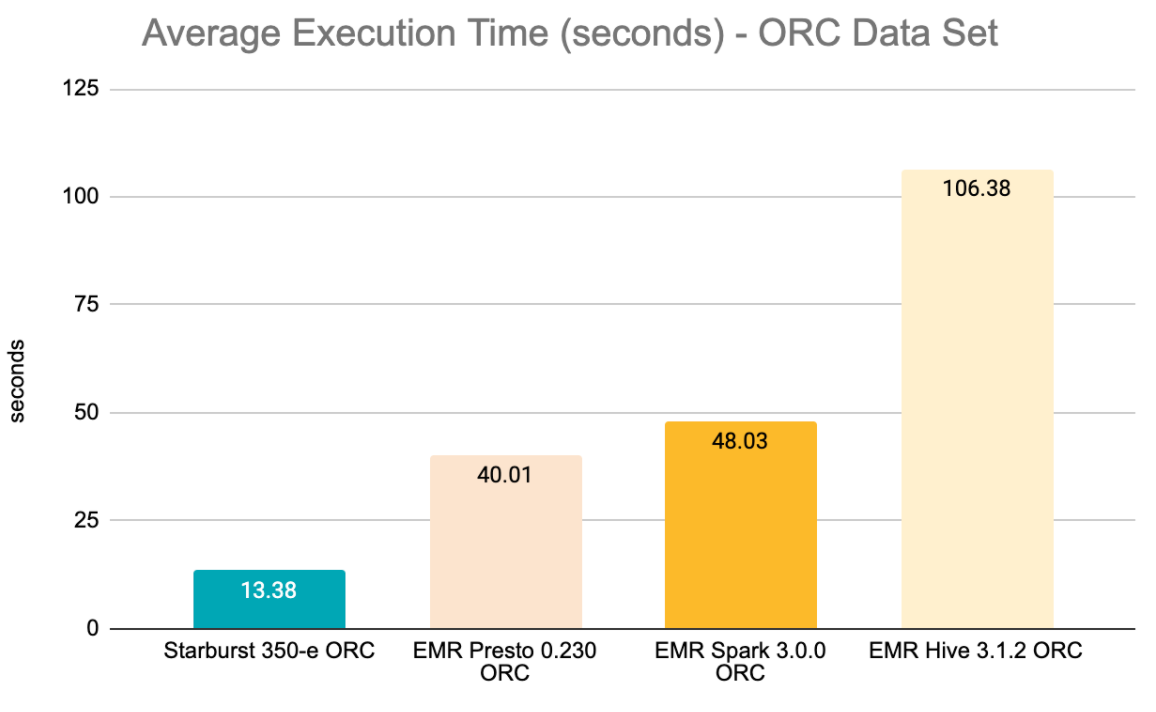
| Avg | 13.38 | 40.01 | 48.03 | 106.38 |
| Max | 72.00 | 501.00 | 402.00 | 1501.25 |
| Min | 0.89 | 1.00 | 23.50 | 17.50 |
The table below shows the average query execution time relative to each engine, as a percentage.
| relative to: | ||||
|---|---|---|---|---|
| EMR Presto 0.230 | EMR Spark 3.0.0 | EMR Hive 3.1.2 LLAP | Starburst 350-e | |
| EMR Presto 0.230 | N/A | 83% | 38% | 299% |
| EMR Spark 3.0.0 | 120% | N/A | 45% | 359% |
| EMR Hive 3.1.2 LLAP | 266% | 221% | N/A | 795% |
| Starburst 350-e | 33% | 28% | 13% | N/A |
Observations for the ORC dataset:
EMR Presto didn’t return any syntax errors, but it returned 2 query execution failures: q4 and q11 (Insufficient Memory). After 30 minutes, I had to cancel execution for q72, so I’m considering that query as failed as well. Excluding these 3 queries, the average execution time for EMR Presto was 40s.
EMR Spark initially returned 36 errors when parsing queries, which were corrected by applying minor updates (mostly adding ` to some strings). For the following 7 queries, I couldn’t find a simple way to fix errors without possibly altering the query structure (and the validity of the test): q21, q34, q53, q58, q62, q75, q83. Excluding those queries, the average query execution time was 48s.
EMR Hive returned syntax errors for the following 17 queries, which similarly to Spark errors I couldn’t find a simple way to fix without possibly affecting the validity of the test: q14, q16, q23, q24, q27, q30, q32, q36, q62, q70, q81, q86, q92, q94, q95.
There were no failures returned by Starburst Enterprise and its average query execution was 13.4 seconds - the fastest among all 4 engines under analysis and it was the only engine that successfully executed all 99 queries. On average, Starburst Enterprise was 2.5x faster compared to EMR Presto, 3.9x faster compared to EMR Spark and 7.1x faster compared to EMR Hive.
Parquet - Performance Comparison
| qid | Starburst 350-e | EMR Presto 0.230 | EMR Spark 3.0.0 | EMR Hive 3.1.2 LLAP |
|---|---|---|---|---|
| q01 | 7 | 13 | 73 | N/A |
| q02 | 22 | 22 | 40 | N/A |
| q03 | 4 | 22 | 28 | 64 |
| q04 | 40 | N/A | 120 | 194 |
| q05 | 16 | 68 | 49 | 211 |
| q06 | 5 | 42 | 71 | 36 |
| q07 | 9 | 25 | 33 | 89 |
| q08 | 6 | 11 | 30 | 37 |
| q09 | 37 | 34 | 48 | 221 |
| q10 | 6 | 28 | 36 | 73 |
| q11 | 22 | N/A | 80 | 139 |
| q12 | 3 | 10 | 74 | 32 |
| q13 | 12 | 70 | 74 | 92 |
| q14 | 83 | 205 | 67 | N/A |
| q15 | 4 | 13 | 32 | 55 |
| q16 | 15 | 28 | 65 | N/A |
| q17 | 9 | 50 | 43 | 72 |
| q18 | 7 | 18 | 41 | 94 |
| q19 | 8 | 28 | 31 | 53 |
| q20 | 3 | 11 | 76 | 34 |
| q21 | 21 | 30 | N/A | N/A |
| q22 | 25 | 19 | 40 | 118 |
| q23 | 78 | 130 | 82 | N/A |
| q24 | 44 | 54 | 68 | N/A |
| q25 | 8 | 35 | 41 | 68 |
| q26 | 5 | 16 | 32 | 85 |
| q27 | 8 | 25 | 34 | N/A |
| q28 | 43 | 43 | 50 | 212 |
| q29 | 12 | 32 | 48 | 174 |
| q30 | 7 | 41 | 73 | N/A |
| q31 | 10 | 34 | 37 | 82 |
| q32 | 3 | 11 | 78 | N/A |
| q33 | 5 | 20 | 34 | 37 |
| q34 | 5 | 17 | N/A | 74 |
| q35 | 7 | 12 | 41 | 138 |
| q36 | 6 | 20 | 33 | N/A |
| q37 | 17 | 17 | 39 | 182 |
| q38 | 11 | 43 | 51 | 162 |
| q39 | 19 | 39 | 71 | 53 |
| q40 | 15 | 65 | 67 | 233 |
| q41 | 1 | 1 | 23 | 18 |
| q42 | 4 | 16 | 29 | 36 |
| q43 | 2 | 22 | 30 | 79 |
| q44 | 18 | 17 | 71 | 216 |
| q45 | 4 | 11 | 31 | 50 |
| q46 | 7 | 24 | 34 | 96 |
| q47 | 33 | 138 | 73 | 107 |
| q48 | 9 | 36 | 72 | 90 |
| q49 | 18 | 84 | 44 | 236 |
| q50 | 13 | 57 | 83 | 245 |
| q51 | 12 | 27 | 49 | 131 |
| q52 | 4 | 16 | 29 | 38 |
| q53 | 5 | 16 | N/A | 81 |
| q54 | 14 | 30 | 37 | 213 |
| q55 | 4 | 15 | 28 | 35 |
| q56 | 5 | 20 | 35 | 37 |
| q57 | 20 | 72 | 77 | 106 |
| q58 | 7 | 49 | N/A | 55 |
| q59 | 27 | 34 | 39 | 212 |
| q60 | 5 | 20 | 35 | 46 |
| q61 | 2 | 31 | 31 | 44 |
| q62 | 11 | 32 | N/A | 189 |
| q63 | 6 | 16 | 78 | 82 |
| q64 | 86 | 137 | 71 | 272 |
| q65 | 19 | 35 | 76 | 152 |
| q66 | 7 | 80 | 37 | 95 |
| q67 | 57 | 532 | 396 | 271 |
| q68 | 11 | 27 | 32 | 48 |
| q69 | 5 | 11 | 36 | 53 |
| q70 | 18 | 35 | 37 | N/A |
| q71 | 8 | 22 | 38 | 52 |
| q72 | 46 | N/A | 76 | N/A |
| q73 | 5 | 13 | 29 | 53 |
| q74 | 17 | N/A | 52 | 126 |
| q75 | 33 | 90 | N/A | 263 |
| q76 | 15 | 33 | 44 | 219 |
| q77 | 11 | 81 | 44 | 49 |
| q78 | 54 | 131 | 72 | 735 |
| q79 | 8 | 27 | 33 | 81 |
| q80 | 26 | 100 | 52 | 249 |
| q81 | 7 | 16 | 73 | N/A |
| q82 | 19 | 24 | 45 | 191 |
| q83 | 6 | 27 | N/A | 39 |
| q84 | 12 | 13 | 69 | 200 |
| q85 | 15 | 25 | 73 | 230 |
| q86 | 5 | 10 | 29 | N/A |
| q87 | 11 | 25 | 54 | 182 |
| q88 | 50 | 84 | 41 | 198 |
| q89 | 6 | 17 | 78 | 84 |
| q90 | 11 | 10 | 31 | 183 |
| q91 | 2 | 47 | 31 | 26 |
| q92 | 3 | 10 | 76 | N/A |
| q93 | 32 | 101 | 70 | 237 |
| q94 | 14 | 36 | 75 | N/A |
| q95 | 35 | 83 | 83 | N/A |
| q96 | 11 | 11 | 30 | 192 |
| q97 | 13 | 31 | 46 | 149 |
| q98 | 3 | 20 | 76 | 36 |
| q99 | 11 | 62 | 75 | 200 |
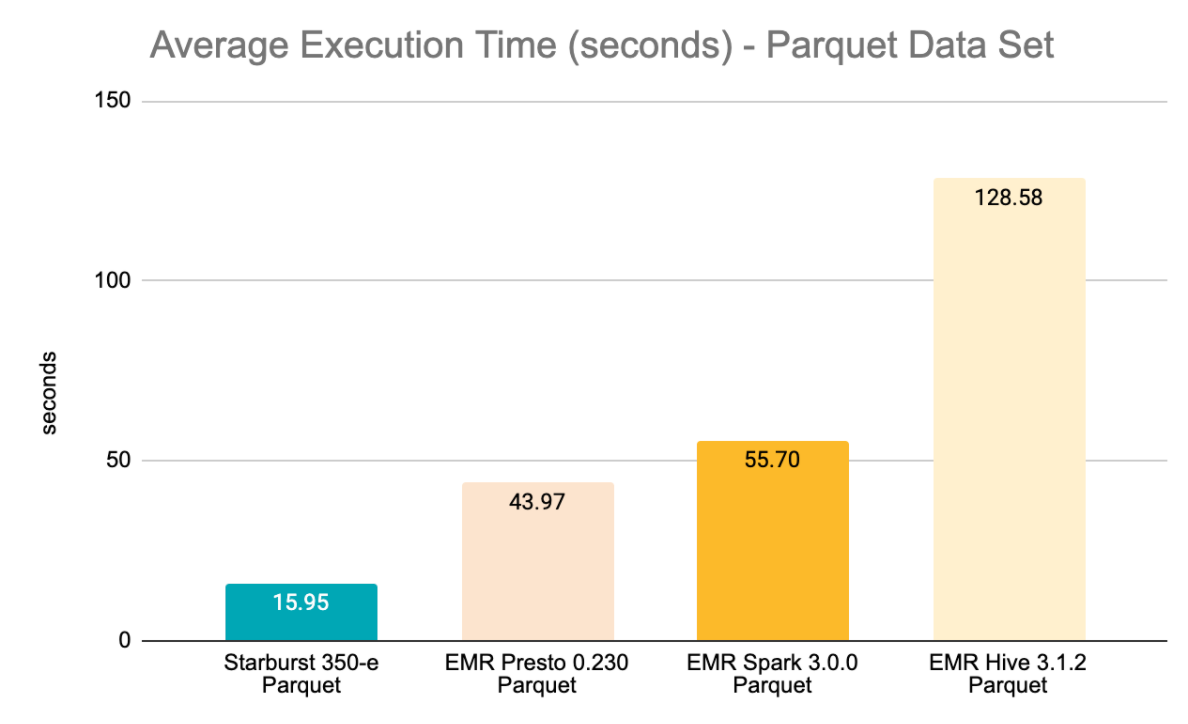
| Avg | 15.95 | 43.97 | 55.70 | 128.58 |
| Max | 85.50 | 531.50 | 396.00 | 735.00 |
| Min | 0.88 | 1.00 | 23.25 | 18.00 |
The table below shows the average query execution time relative to each engine, as a percentage:
| relative to: | ||||
|---|---|---|---|---|
| EMR Presto 0.230 | EMR Spark 3.0.0 | EMR Hive 3.1.2 LLAP | Starburst 350-e | |
| EMR Presto 0.230 | N/A | 79% | 34% | 276% |
| EMR Spark 3.0.0 | 127% | N/A | 43% | 349% |
| EMR Hive 3.1.2 LLAP | 292% | 231% | N/A | 806% |
| Starburst 350-e | 36% | 29% | 12% | N/A |
Observations for the Parquet dataset:
EMR Presto experienced the same errors as in the ORC execution, with the addition of q74 (Insufficient Memory), for a total of 4 failures. Excluding these 4 queries, the average execution time for EMR Presto was 44s.
EMR Spark returned the same 36 errors as in the ORC execution and the same 7 queries could not be fixed (q21, q34, q53, q58, q62, q75, q83). Excluding those queries, the average query execution time was 55.7s.
All EMR Hive errors in the Parquet executions are the same as ORC (ParseException). The only additional error in EMR Hive Parquet executions is q72, which I had to cancel after 30mins. Excluding failed queries, the average query execution time was 128.6s.
Starburst Enterprise didn’t return any failures and its average query execution was approximately 16 seconds - the fastest among all 4 engines under analysis. On average, Starburst Enterprise was 2.38x faster compared to EMR Presto, 3.45x faster compared to EMR Spark and 9.1x faster compared to EMR Hive.
ORC vs. Parquet Summary
Starburst Enterprise executed all queries successfully in both ORC and Parquet formats. EMR Presto returned one additional error in Parquet (q74: Insufficient Memory) compared to ORC. For EMR Hive, I had to cancel q72 after 30 minutes in the Parquet test.
The following table shows average execution times for each engine and data format. In general, all four engines performed better when querying ORC data vs. Parquet.
Average execution (seconds):
| Engine | ORC | Parquet | ORC vs. Parquet |
|---|---|---|---|
| Starburst 350-e | 13.38 | 15.95 | 83.9% |
| EMR Presto 0.230 | 40.01 | 43.97 | 91.0% |
| EMR Spark 3.0.0 | 48.03 | 55.70 | 86.2% |
| EMR Hive 3.1.2 LLAP | 106.38 | 128.58 | 82.7% |
AWS Cost Analysis
The following table compares the cost of running a cluster consisting of 20 executors + 1 coordinator in the N. Virginia region as well as a monthly projection assuming 720 hours per month for an always-on cluster.
Both EMR and Starburst Enterprise share a pricing model where you pay the regular EC2 instance compute fee plus a license fee.
| Starburst Enterprise | EMR | |||||
|---|---|---|---|---|---|---|
| Component | Price Dimension | Usage | Hourly Cost | Monthly Cost | Hourly Cost | Monthly Cost |
| Data store | 234GB (ORC) | 234GB | $0.01 | $5 | $0.01 | $5 |
| Executor + Coordinator Nodes | EC2 Compute | 11 r5.8xlarge instances | $22.18 | $15,966.72 | $22.18 | $15,966.72 |
| Starburst Presto Enterprise License | AWS Marketplace ($0.799/hour for 1 r5.8xlarge) | 11 r5.8xlarge instances | $8.79 | $6,328.08 | N/A | N/A |
| EMR Fee | $0.252/hr (r5.4xlarge) | 11 r5.8xlarge instances | N/A | N/A | $2.97 | $2,138.40 |
| Hive Metastore | EC2 Compute + EMR fee | 1 m4.large | $0.12 | $86.40 | N/A | N/A |
| RDS MySQL | Hive Metastore storage | 1 db.t3.medium | $0.07 | $48.96 | $0.07 | $48.96 |
| EBS Storage | EBS Volume Usage - gp2 | 50GB x 11 = 550GB | $0.08 | $55.00 | $0.08 | $55.00 |
| Data Transfer | S3 to EC2 - Intraregional Data Transfer | N/A | $0.00 | $0.00 | $0.00 | $0.00 |
| $31.24 | $22,490.54 | $25.30 | $18,214.46 |
License costs are 60% higher for Starburst Enterprise compared to EMR ($0.40/hour vs. $0.25/hour per each r5.4xlarge EC2 instance). The monthly license cost for a 21-node, always-on, cluster would be $3.8K for EMR, compared to $6K for Starburst Enterprise. EMR supports per-second billing, while Starburst Enterprise bills per hour.
However, it’s worth noting that the average execution took Starburst Enterprise a fraction of the time it took other engines running on EMR (between 12% and 36% on average). Results will vary according to your specific needs, but having a faster tool will result in less compute time consumed. With this in mind and applying usage-based scaling, I think it’s fair to expect at least 50% savings when using Starburst Enterprise.
AWS Cost Management Recommendations
If not managed properly, Big Data analytics workloads can easily turn into costly deployments. Therefore it’s important to apply as many optimization strategies as possible. Here are some recommendations:
- Workloads often result in many TBs of data being transferred across different servers and data sources, which can easily turn into high data transfer costs. Here are two areas to pay special attention to:
- Inter-regional Data Transfer. In order to avoid intra-regional data transfer fees, it’s important to ensure S3 buckets (or any data sources) are deployed in the same AWS region as EC2 instances or Fargate containers. Otherwise, you should expect inter-regional data transfer fees between S3 and compute nodes. These charges can range between $10 and even close to $150 per TB, depending on the origin and destination regions. Most regions in the US result in $20 per TB for inter-regional data transfer. Also, performance will be much better if all components are deployed in the same region.
- Intra-regional Data Transfer. Even though in most applications it’s a good practice to deploy compute resources across multiple Availability Zones, for many big data analysis deployments this can turn out to be expensive. Data transfer across AZs in the same region costs $10/TB in each direction. Given that clusters usually transfer large amounts of data across nodes, this cost can add up over time (I’ve seen it reach a few thousand dollars per month in some cases). If your use case can handle a situation without extra AZ redundancy, you could save money by deploying all compute resources in the same AZ.
- Always use automation tools, such as custom scripts or CloudFormation templates. This way clusters can be terminated or adjusted easily, resulting in cost savings. Starburst Enterprise provides a CloudFormation template, which simplifies the provisioning of clusters. EMR has a number of APIs and CLI commands available that simplify cluster management automation.
- Both EMR and Starburst Enterprise support Auto Scaling. I recommend applying rules that decrease cluster size to a minimum during idle periods, based on CPU Utilization metrics. You can also configure Scheduled Actions to decrease cluster size outside of high utilization hours.
- Always consider purchasing EC2 Reserved Instances or Savings Plans. There are a number of variables to consider before purchasing EC2 Reserved Instances, the most important one being the type of compute capacity that you’ll need in the long run. I wrote two articles about this, one for EC2 and one for EMR, which will give you more details. Spot Instances are always an option. You only have to make sure that your use case supports a situation where instances get terminated in the middle of an execution. You can achieve savings of close to 80% compared to EC2 On Demand cost.
Conclusions
- For the ORC dataset, on average Starburst Enterprise was 2.5x faster compared to EMR Presto, 3.84x faster compared to EMR Spark and 7.14x faster compared to EMR Hive with LLAP enabled.
- For the Parquet dataset, on average Starburst Enterprise was 2.38x faster compared to EMR Presto, 3.45x faster compared to EMR Spark and 7.14x faster compared to EMR Hive with LLAP enabled.
- Starburst Enterprise successfully executed all 99 queries in scope. Excluding query syntax errors, EMR Presto returned 3 failures in the ORC dataset and 4 failures in the Parquet dataset due to Insufficient Memory errors. Also, excluding query syntax errors, EMR Hive Parquet execution had to be cancelled for q72 after 30mins of execution. EMR Spark didn’t result in execution times beyond 30 minutes or failed executions due to memory errors, without considering the 7 queries that could not be parsed.
- Even though license costs are 60% higher for Starburst Enterprise compared to EMR ($0.40/hour vs. $0.25/hour per each r5.4xlarge EC2 instance), the higher performance delivered by Starburst will result in lower compute cost compared to EMR. Most likely 50%-70% lower depending on the type of workload and usage patterns.
Considering cost, performance and infrastructure setup, Starburst Enterprise is definitely an option that should be considered for data analytics workloads in AWS. While EMR provides a solid solution and a wide range of platforms, for this set of tests Starburst Enterprise delivered better results compared to EMR.
Do you need help optimizing your Big Data workloads in the cloud?
I can help you optimize your Big Data workloads in the cloud and make sure they deliver the right balance between performance and cost for your business. Click on the button below to schedule a free consultation or use the contact form.
